 菡萏如佳人
菡萏如佳人文章目录
1 基础篇—千里之行始于足下
基于redis6
安装与运行
无论你一名极客还是一名工程师,Redis安装我都推荐源码安装,请前往官方下载地址:http://redis.io/download 进行源码下载,偶数为稳定版 奇数为不稳定版。
如果你是类linux系统,使用wget命令直接远程下载源码 wget https://download.redis.io/releases/redis-{具体版本号}.tar.gz
编译与安装命令:make && make install
默认安装地址:/usr/local/bin,准备好redis.conf配置文件,以下几个配置建议修改:
daemonize yes 后台启动
port xxxx 修改默认端口
requireoass xxxx 添加访问密码
bind 127.0.0.1 如果想其它服务器可以访问,注释掉
服务端启动运行命令: ./redis-server ../conf/redis.conf
服务端停止运行命令:pkill redis-server 或者使用客户端发出关闭命令: ./redis-cli shutdown
客户端链接命令:./redis-cli -h 服务器IP -p 端口 -u 用户 -a 密码,建议更换默认端口,添加访问认证密码
redis版本号查看命令:redis-server -v
redis自带工具集
- redis-benchmark:性能测试工具,测试redis在你的系统及配置下的读写性能
- redis-check-aof:用于修复出问题的AOF
- redis-check-rdb:用于修复出问题的rdb
- redis-sentinel:redis的集群管理工具
两种线程模型
- 单线程模型:socket读写、解析数据、执行处理、返回数据等操作都是由一个主线程来完成的。通过对epoll函数的包装来做到。
单线程原因:瓶颈在内存和网络不在cpu、多线程可能不安全、复杂度增加、线程上下文切换性能损耗等
- 多线程模型:redis6开始支持I/O多线程,因为之前的瓶颈主要在I/O数据读写性能
高性能根本原因:抽象了一套事件模型,使用多路复用机制(epoll),使得I/O读写都是非阻塞的,从而具备高性能的网络处理能力;同时基于内存进行数据处理。
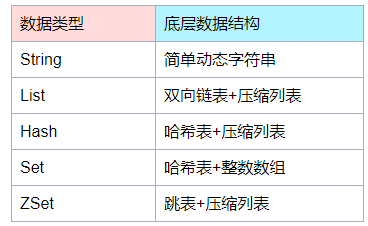
value存储形式
我们日常中所提到的String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)都只是Redis 键值对中值的数据类型,也就是数据的保存形式。
严格来说并不是Redis数据结构,Redis底层数据结构实现其实一共有6种:分别是简单动态字符串(SDS)、双向链表、压缩列表、哈希表、跳表和整数数组。具体对应关系,后面介绍底层存储结构时会进一步介绍。
先理解和掌握value的5种基本存储形式
String
key是字符串,如果存在空格必须加上双引号,最大的容量是512M

类似Memcache的键值存储,
- 使用场景:缓存、计数、共享会话、限速
List
底层实现是链表
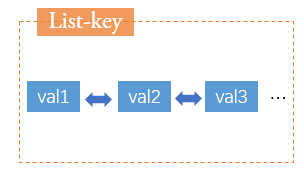
类似数据结构中的队列,不过支持双向操作。
- 使用场景:消息队列、文章列表
Hash
按hash的方式存放字符串
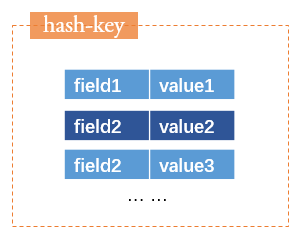
相当于关系数据的行数据
- 使用场景:存储类似于关系数据库的行
Set
是通过hashTable实现的
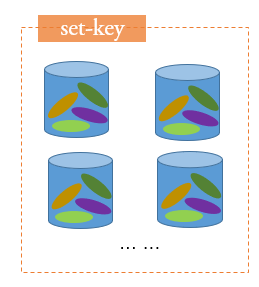
存储很多数据名单又不重复,判断某个元素是否存在相当方便,聚合运算效率也很高(存放好友,联系人,共同好友)
- 使用场景:标签,分类,社交
Zet
是通过散列表和跳跃表来实现的
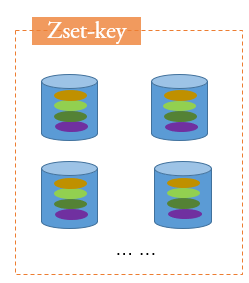
在Set基础上增加了有序的特点,增加了一个double类型的分数作为权重,用于排序
- 使用场景:排行榜、社交点赞
存储基本结构
整体上看,无论是哪种存储形式,Redis都是键-值的形式,为了实现这种从键到值的快速访问,Redis使用了一个哈希表来保存所有的键值对。
一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。

每个键值对包含了键部分和值部分,键部分都是String类型,值部分由大家所熟知的(上面介绍的)5种存储结构组成,而底层用来实现的数据结构有6种,它们之间的对应关系如下:
上面这个哈希表保存了所有的键值对,也称作全局哈希表。当Hash表查询数据的时间复杂度是O(1),操作又是内存级别的,所以数据会非常快。
不过当redis存储的数据越来越大的时候,难免就会产生hash冲突,形成链式hash,hash链上的元素只能逐个查找,时间复杂度是O(n),所以效率就会下降。
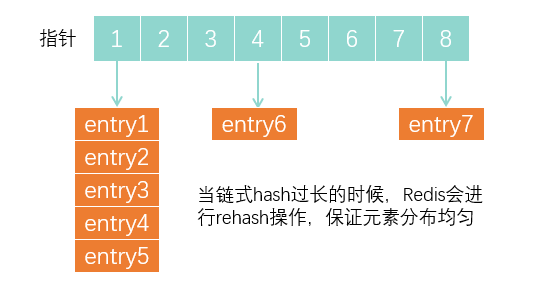
当链式hash过程的时候,redis会进行rehash操作,保证元素分布均匀。rehahs的过程是一个渐进式的过程。可以分为3个步骤:
1 先构造一个更大的全局哈希表;
2 映射元素到新的全局哈希表;
3 释放掉旧的hash表。
这里的关键是第2步,redis不是一次性完成所有元素拷贝的,而是在某索引位置发生请求或空闲时,才进行拷贝。
巧妙的把一次性大量拷贝分摊到了多次请求的过程中,既不影响正常请求也能保证数据快速拷贝(后续AOF重写技术也利用了这个设计)。
熟悉了底层数据结构的实现,对我们如何使用redis提供了技术指导,操作的复杂度取决于数据结构的复杂度:
- 对Hash和Set的单元素操作,其实现是哈希表,复杂度都是O(1),它们现在也支持了多元素操作,M个元素复杂度就是O(M)
- 对List、Hash、Set遍历操作时其实现是通过链表或数组实现,复杂度一般为O(N),我们尽量避免这种操作
- 对集合类型元素统计操作(LLEN,SCARD),一般会有单独的字段来存储这个值,所以复杂度为O(1)
- 特别注意对与压缩列表和双向列表都会记录头尾指针偏移量,对与头尾类操作(LPOP,RPUSH),复杂度为O(1)
通用规则
- List、Hash、Set、Zset被称作容器型数据
- 不存在就创建原则:容器型数据不存在,就会自动创建一个,再进行操作
- 没有就释放原则:容器型数据中如果没有元素了,就删除掉并释放内存
- 能有过期时间:所有数据结构都可以设置过期时间
- 过期时间擦除:对有过期时间的字符串进行修改操作会抹除掉过期时间

过期机制
设计理念基于性能与效率的折中,采用定期删除与惰性删除机制
定期删除:Redis会在后台,默认每秒10次的执行如下操作: 随机 选取100个key校验是否过期,如果有25个以上的key过期了,立刻 额外随机选取下100个key(不计算在10次之内)。也就是说,如果过 期的key不多,Redis最多每秒回收200条左右,如果有超过25%的 key过期了,它就会做得更多,这样即使从不被访问的数据,过期 了也会被删除掉。
惰性删除:当client主动访问key时,会先对key进行超时判断,过 时的key会立刻删除
处理过期keys的相关命令:
- expire:设置过期时间,格式是expire key值 秒数
- expireat:设置过期时间,格式是expireat key值 到秒的时间戳
- ttl:查看还有多少秒过期,格式是ttl key值,-1表示永不过期,-2表示已 过期
- persist:设置成永不过期,格式是persist key值,删除key的过期设置;另 外使用set或者getset命令为键赋值的时候,也会清除键的过期时间
- pttl:查看还有多少毫秒过期,格式是pttl key值
- pexpire:设置过期时间,格式是pexpire key值 毫秒数
- pexpireat:设置过期时间,格式是pexpireat key值 到毫秒的时间戳
附录一:常用命令
1 连接操作命令
- quit:关闭连接(connection)
- auth:简单密码认证
- help cmd: 查看cmd帮助,例如:help quit
2 持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shundown:将数据同步保存到磁盘,然后关闭服务
3 远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
4 对key操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key(?、*、[]、\x等通配符)
- randomkey:随机返回key空间的一个
- keyrename(oldname, newname):重命名key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):切换到某个数据库(更像是命名空间)
- move(key, dbindex):移动当前数据库中的key到dbindex数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
5 String
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string的value
- setnx(key, value):添加string,名称为key,值为value
- setex(key, time, value):向库中添加string,设定过期时间time
- mset(key N, value N):批量设置多个string的值
- msetnx(key N, value N):如果所有名称为key i的string都不存在
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
6 List
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的 元素
-
lpushx/rpushx:只有当list存在时才会从左/右边依次追加元素
-
linsert:插入元素,格式是linsert list的key before|after 定 位查找的值 添加的值
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素
- ltrim(key, start, end):截取名称为key的list
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值
- lrem(key, count, value):删除count个key的list中值为value的元素,0表示全部
- lpop(key):返回并删除名称为key的list中的首元素
- rpop(key):返回并删除名称为key的list中的尾元素
- blpop(key1, key2,… key N, timeout):lpop命令的block版本。
- brpop(key1, key2,… key N, timeout):rpop的block版本。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
7 Set
-
sadd(key, member):向名称为key的set中添加元素member,member可以有多个
-
smembers(key) :返回名称为key的set的所有元素
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :移到集合元素
- scard(key) :返回名称为key的set的基数
-
sismember(key, member) :member是否是名称为key的set的元素
-
srandmember(key) :随机返回名称为key的set的一个元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
- sunion(key1, (keys)) :求并集
- sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
- sdiff(key1, (keys)) :求差集,保留key1独有
- sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
8 Hash
- hset(key, field, value):向名称为key的hash中添加元素field
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, (fields)):返回名称为key的hash中field i对应的value
-
hmset(key, (fields)):向名称为key的hash中添加元素field
-
hsetnx:如果项不存在则赋值,存在时什么都不做,格式是 hsetnx Hash的Key 项的key 项的值
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
-
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
-
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
-
hincrbyfloat:增减Float数值,格式是hincrbyfloat Hash的Key 项的key 正负float
9 Zset
- zadd:添加元素,格式是zadd zset的key score值 项的值,Score 和项可以是多对,score可以是整数,也可以是浮点数,还可以是 +inf表示正无穷大,-inf表示负无穷大
- zrange:获取索引区间内的元素,格式是zrange zset的key 起始 索引 终止索引 (withscores)
- zrangebyscore:获取分数区间内的元素,格式是zrangebyscore zset的key 起始score 终止score (withscores),默认是包含端点 值的,如果加上“(”表示不包含;后面还可以加上limit来限制
- zrem:删除元素,格式是zrem zset的key 项的值,项的值可以是 多个
- zcard:获取集合中元素个数,格式是zcard zset的key
- zincrby:增减元素的Score,格式是zincrby zset的key 正负数 字 项的值
- zcount:获取分数区间内元素个数,格式是zcount zset的key 起 始score 终止score
- zrank:获取项在zset中的索引,格式是zrank zset的key 项的值
- zscore:获取元素的分数,格式是zscore zset的key 项的值,返 回项在zset中的score
- zrevrank:获取项在zset中倒序的索引,格式是zrevrank zset的 key 项的值
- zrevrange:获取索引区间内的元素,格式是zrevrange zset的 key 起始索引 终止索引 (withscores)
- zrevrangebyscore:获取分数区间内的元素,格式是 zrevrangebyscore zset的key 终止score 起始score (withscores)
- zpopmax:从集合中弹出分数最高的成员,返回该成员和分值,然后从集合 中将其移出
- zpopmin:从集合中弹出分数最低的成员,返回该成员和分值,然后从集合 中将其移出
- bzpopmax:在参数中的所有集合均为空的情况下,阻塞连接。参数中包含多 个有序集合时,按照参数中key的顺序,返回第一个非空key中分数最大的成 员和对应的分数。参数 timeout 可以理解为客户端被阻塞的最大秒数值,0 表示永久阻塞。
- bzpopmin:在参数中的所有集合均为空的情况下,阻塞连接。参数中包含多 个有序集合时,按照参数中key的顺序,返回第一个非空key中分数最小的成 员和对应的分数。参数 timeout 可以理解为客户端被阻塞的最大秒数值,0 表示永久阻塞。
- zremrangebyrank:删除索引区间内的元素,格式是 zremrangebyrank zset的key 起始索引 终止索引
- zremrangebyscore:删除分数区间内的元素,格式是命令 zset 的key 起始score 终止score
- zinterstore:交集,格式是ZINTERSTORE dest-key key-count key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
- zunionstore:并集,格式是ZUNIONSTORE dest-key key-count key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
10 Sort排序
可以使用sort命令对List、Set、ZSet里面的值进行排序
SORT source-key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE dest-key]
by:设置排序的参考键,可以是字符串类型或者是Hash类型里面的 某个Item键,格式是 Hash键名:->Item键。设置了by参考键, sort将不再依据元素的值来排序,而是对每个元素,使用元素的值 替换参考键中的第一个””,然后获取相应的值,再对获得的值 进行排序。如果参考键不存在,默认为0。如果参考键值一样,再以元素本身的值进行排序。
get:指定sort命令返回结果包含的键的值,形如: Hash键名:*- >Item键,可以指定多个get,返回的时候,一行一个。如果要返回 元素的值,用get #。
- 对较大数据量进行排序会严重影响性能,所以:1 尽量减少排序集合中数据;2 使用limit限制获取数据量;3 可以考虑使用Store来缓存结果
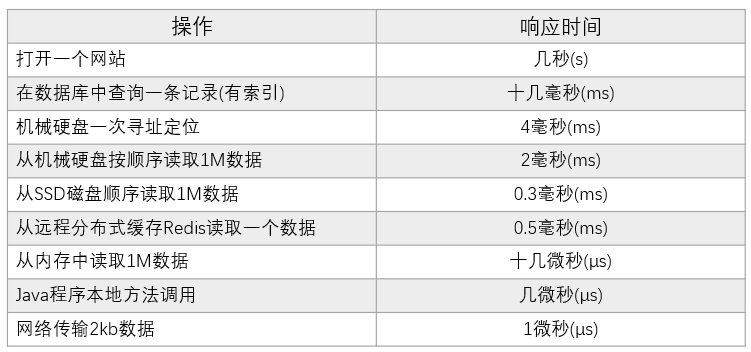
附录二:对于多快常识
附录三:配置文件
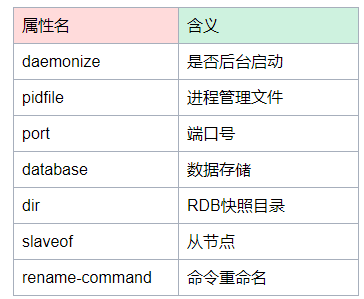
可以在redis-cli里面使用config命令来获取或者设置Redis 配置,这样可以做到不用重新启动Redis来改变配置(仅支持部分配置)。
命令: config get/set 配置名
不支持动态配置的属性有(不是全部):
注意:只推荐在开发和测试环境使用!重启后失效!
配置分类
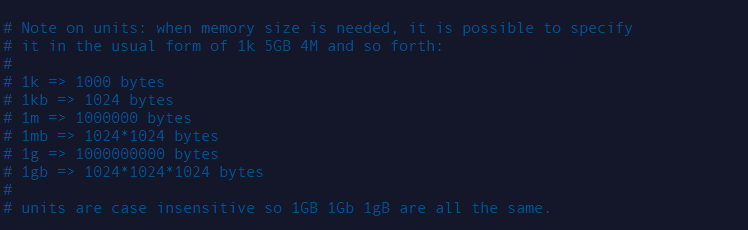
Redis定义了一些基本的度量单位,只支持bytes,不支持bit,配置对带小写不敏感
Redis配置文件(基于6.0版本)中可以配置的内容根据其作用分,大致包含24种:
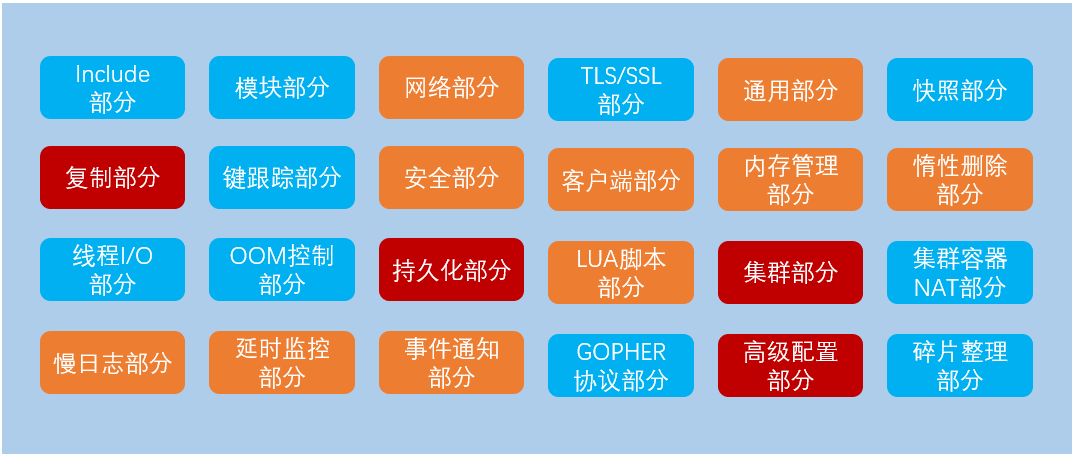
这里简单罗列下项目开发中可能经常用到的部分(橙色),红色部分以及相关配置会放在后续专门的主题中来进行介绍,基本可以通过阅读配置文件注释来得到使用方法
网络部分
- bind:Redis服务监听地址,用于客户端连接,默认本机地址
- protected-mode :安全保护模式,默认开启,配置bind ip或者设置访问密码访问,关闭后,外部网络可以直接访问
- port:监听的端口号,默认服务端口是6379(强烈建议更换)
- tcp-backlog:设置tcp的backlog,backlog其实是一个已经完成三次握手的连接队列,默认是511。在高并发环境下,需要一个高 backlog值来避免慢客户端连接问题。注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值,所以需要确认增大 somaxconn和tcp_max_syn_backlog两个值来达到想要的效果
- unixsocket:指定 unix socket 的路径
- unixsocketperm:指定 unix socket file 的权限
- timeout:连接空闲超时时间,0表示永不关闭,默认值
- tcp-keepalive:单位为秒,如果设置为0,则不会进行Keepalive 检测,建议设置成60,默认是300
通用部分
- daemonize:是否以后台daemon方式运行,默认是no
- supervised:可以通过upstart和systemd管理Redis守护进程,这个参数是和具体的操作系统相关的
- pidfile:pid进程文件位置,默认会生成在/var/run/redis.pid,启动多个时候配置到不同目录
- loglevel:log信息级别,共分四级,即debug、verbose、notice 、warning
- logfile:log文件位置,如果设置为空字符串,则redis会将日志 输出到标准输出。假如你在daemon情况下将日志设置为输出到标准 输出,则日志会被写到/dev/null中
- syslog-enabled:是否把日志输出到syslog中
- syslog-ident:指定syslog里的日志标志
- syslog-facility:指定syslog设备,值可以是USER或LOCAL0- LOCAL7
- databases:开启数据库的数量,编号从0开始,默认的数据库是编号为0的数据库,可以使用select来选择相应的数据库
- always-show-logo:是否显示Redis的ASCII艺术logo
安全部分
- acllog-max-len:ACL日志存储在内存中并消耗内存,设置此项可以设置最大值来回收内存
-
requirepass:设置Redis连接密码
-
rename-command:将命令重命名。为了安全考虑,可以将某些重要的、危险的命令重命名。当你把某个命令重命名成空字符串的时候就等于取消了这个命令
客户端部分
- maxclients:设置redis同时可以与多少个客户端进行连接。
默认情况下为10000个客户端。当你无法设置进程文件句柄限制时, redis会设置为当前的文件句柄限制值减去32,因为redis会为自身内部处理逻辑留一些句柄出来。
如果达到了此限制,redis则会拒 绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。
内存管理部分
- maxmemory:设置redis可以使用的内存量,最多是物理机的一半。
一旦到达内存使用上限 ,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
如果redis无法根据移除规则来移除内存中的数据 ,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
但是对于无内存申请的指令,仍然会正常响应,比如GET等。
如果你的redis是主redis(说明你的还有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。
- maxmemory-samples:设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key 并选择其中LRU的那个。
-
maxmemory-policy:设置内存移除规则
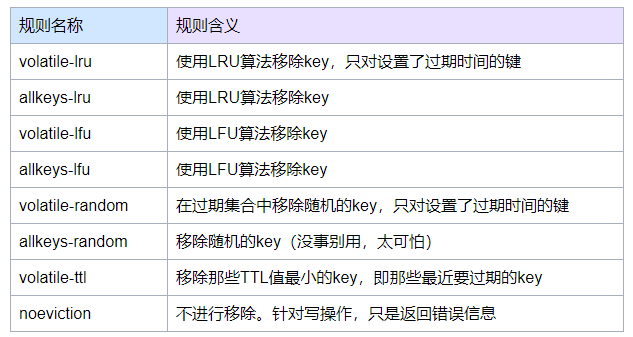
注意:无论使用上述哪一种移除规则,如果没有合适的key可以移除的话,redis都 会针对写请求返回错误信息
- replica-ignore-maxmemory:从 Redis 5 开始,默认情况下,replica 节点会忽略 maxmemory 设置(除非在发生 failover 后,此节点被提升为 master 节点)。
这意味着只有 master 才会执行过期删除策略,并且 master 在删除键之后会对 replica 发送 DEL 命令。
惰性删除部分
- lazyfree-lazy-eviction:对redis内存使用达到maxmeory,并设置有淘汰策略时,在被动淘汰键时,是否采用lazy free机制。
因为此场景开启lazy free, 可能使用淘汰键的内存释放不及时,导致redis内存超用,超过 maxmemory的限制,一般不启用
- lazyfree-lazy-expire:对设置有TTL的键,达到过期后,被redis清理删除 时是否采用lazy free机制。此场景建议开启,因TTL本身是自适应调整的速度
-
lazyfree-lazy-server-del:对有些指令在处理已存在的键时,会带有一个 隐式的DEL键的操作。
如rename命令,当目标键已存在,redis会先删除目标键,如果这些目标键是一个big key,那就会引入阻塞删除的性能问题。 此参数设置就是解决这类问题,建议可开启
- replica-lazy-flush:对slave进行全量数据同步,slave在加载 master的RDB文件前,会运行flushall来清理自己的数据场景,参数设置决定是否采用异常flush机制。
如果内存变动不大,建议可开启。可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起 的内存使用增长
- lazyfree-lazy-user-del:修改DEL的默认行为,使得命令的行为 完全像UNLINK
脚本与日志部分
-
lua-time-limit:设置lua脚本的最大运行时间,单位是毫秒,如果此值设置为0或负数,则既不会有报错也不会有时间限制,默认是5秒
-
slowlog-log-slower-than:判断是否慢日志的执行时长,单位是微秒,负数则会禁用慢日志功能,而0则表示强制记录每一个命令
-
slowlog-max-len:慢日志的长度。当一个新的命令被写入日志时 ,最老的一条会从命令日志队列中被移除
监控与事件部分
-
latency-monitor-threshold:能够采样不同的执行路径,来知道 redis阻塞在哪里,这使得调试各种延时问题变得简单,设置一个 毫秒单位的延时阈值来开启延时监控
-
notify-keyspace-events:设置是否开启Pub/Sub 客户端关于键空间发生的事件,有很多通知的事件类型,默认被禁用,因为用户通常不需要该特性,并且该特性会有性能损耗,设置成空字符串就是禁用