 菡萏如佳人
菡萏如佳人文章目录
4 Repository 中的方法返回值使用
Repository 返回结构有哪些?
打开 SimpleJpaRepository 直接看它的 Structure 就可以知道,它实现的方法,以及父类接口的方法和返回类型包括:Optional、Iterable、List、Page、Long、Boolean、Entity 对象等,而实际上支持的返回类型还要多一些。
由于 Repository 里面支持 Iterable,所以其实 java 标准的 List、Set 都可以作为返回结果,并且也会支持其子类,Spring Data 里面定义了一个特殊的子类 Steamable,Streamable 可以替代 Iterable 或任何集合类型。
Steamable
这里单独介绍下Steamable,它是一个函数式接口,它继承了Iterable,所以使用它我们可以很方便的返回集合类型的数据。
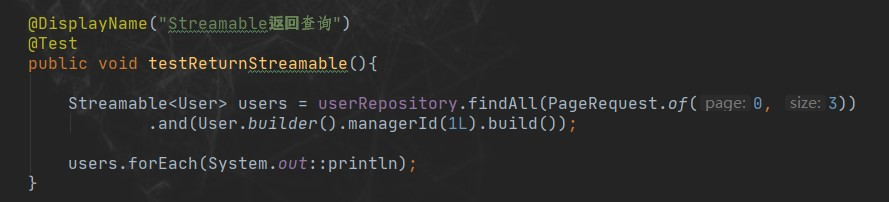
官方给我们提供了自定义 Streamable 的方法,不过在实际工作中很少出现要自定义保证结果类的情况。其原理很简单,就是实现Streamable接口,自己定义自己的实现类即可
List/Stream/Page/Slice
- List:根据条件纯列表式返回
- Stream:通过使用 Java 8 Stream 作为返回类型来逐步处理查询方法的结果,要注意流的关闭
- Page:带分页信息的返回,分页信息中包含:数据内容、分页数据、当前数据描述等信息。数据量大的时候避免使用,会隐含一次count(*)操作
- Slice:只查询偏移量,不计算分页数据的返回,不关心总页数。这就是 Page 和 Slice 的主要区别,现代分页方式推荐这种方式的查询
Future /CompletableFuture 异步结果返回
@Async
Future<User> findByFirstname(String firstname);
@Async
CompletableFuture<User> findOneByFirstname(String firstname);
@Async
ListenableFuture<User> findOneByLastname(String lastname);
在实际工作中,直接在 Repository 这一层使用异步方法的场景不多,一般都是把异步注解放在 Service 的方法上面,这样的话,可以有一些额外逻辑,如发短信、发邮件、发消息等配合使用。使用异步的时候一定要配置线程池,这点切记,否则“死”得会很难看。万一失败我们会怎么处理?关于事务是怎么处理的呢?这种需要重点考虑的
Reactive 支持
其实Common里面提供的只是接口,而JPA里面没有做相关的Reactive 的实现,但是本身Spring Data Common里面对 Reactive 是支持的。如果我们引入spring-boot-starter-data-mongodb的依赖,会发现它天然地支持着 Reactive 这条线。这些内容会放在后续mongodb专题中讲解
返回结果小结
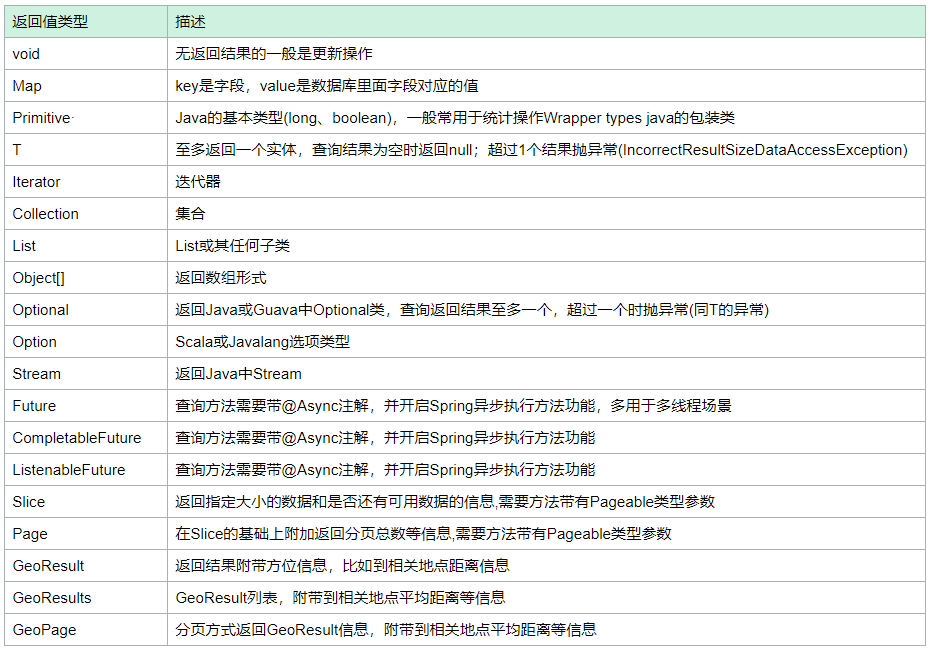
下表列出了 Spring Data JPA Query Method 机制支持的方法的返回值类型
DTO返回结果支持哪些
比较规范的开发团队中都会有这么一条规范:不能暴露底层数据结构,也就是不允许将实体entity直接返回给出去,所以就诞生出了VO/DTO/DO/PO等概念。
于是在开发中我们必须自己去写各种DO/DTO/VO之间转换,同时还产生了各种工具类:BeanUtil、Mapstruct、Dozer、Orika、ModelMapper、Jmapper等(比较推荐Mapstruct综合性能最佳)
Spring Data 正是考虑到了这一点,引入了Projections映射这一概念, 它指的是和 DB 的查询结果的字段映射关系。允许对专用返回类型进行建模,有选择地返回同一个实体的不同视图对象。
如果我们的User只需要返回name和email,那应该怎么做呢?
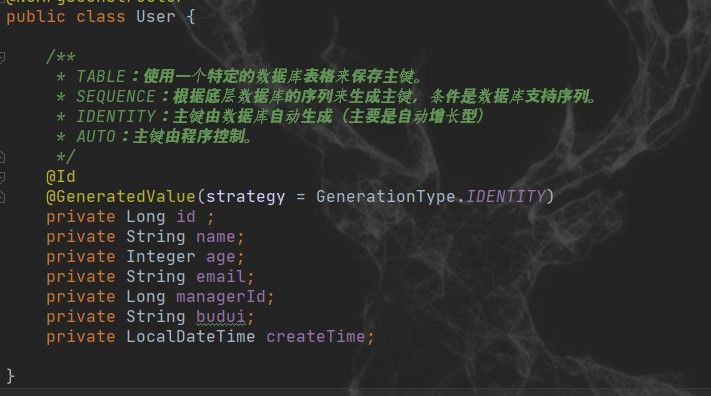
方法一:新建实体类和资源库

然后,新增一个 UserOnlyNameEmailEntityRepository,做单独的查询

很显然这种方法比较糟糕,当存在多种返回值的情况,我们难道要定义多个实体类和资源库吗?
当然这种方式也并非一无是处,对那些临时需求,奇葩需求,生命周期和演化方向不同需求,为了保证我们架构和代码的整洁性与业务可扩展性,我们这么做也不一种蛮不错的选择
方法二:定义DTO方式
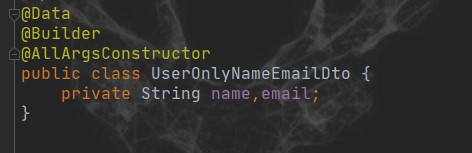
然后定义单独的查询方法
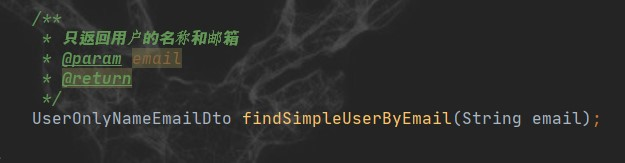
下面是测试结果代码:


这里需要注意的是,如果我们去看源码的话,看关键的 PreferredConstructorDiscoverer 类时会发现,UserDTO 里面只能有一个全参数构造方法。
所以这种方式的优点就是返回的结果不需要是个实体对象,对 DB 不能进行除了查询之外的任何操作;缺点就是因为DTO要实现转化必须要有set方法,一旦有 set 方法就可以改变里面的值,构造方法不能更改,必须全参数,这样如果是不熟悉 JPA 的新人操作的时候很容易引发 Bug
方法三:POJO接口方式
这种方式与上面两种的区别是只需要定义接口,它的好处是只读,不需要添加构造方法,我们使用起来非常灵活,一般很难产生 Bug

仍然定义一个单独的查询方法:
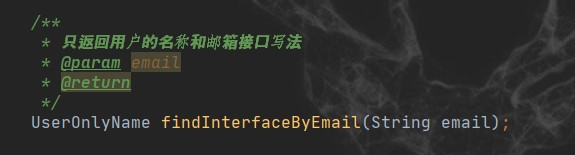
下面是测试代码:


这个时候会发现我们的 userOnlyName 接口成了一个代理对象,里面通过 Map 的格式包含了我们的要返回字段的值(如:name、email),我们用的时候直接调用接口里面的方法即可,如 userOnlyName.getName() 即可;这种方式的优点是接口为只读,并且语义更清晰。(DTO/VO转换貌似有点不方便)
总结
如果不熟悉JPA各种返回值和特点,我们很难在实际项目中选择正确的使用方法。
越容易上手的技术其实越难以恰到好处的使用。就像Springboot出现后,许多不懂Spring的开发人员一旦遇到问题完全是只能百度和谷歌,如果搜不到,完全就处于懵逼状态,目前有太多的开发人员连二者的区别都弄不清楚。
JPA的使用看起来非常方便,如果没有进一步理解,很容易误用和乱用,从而导致性能和数据安全性方面的问题。使用SpringDataJPA非常简单,但是要用好SpringDataJPA我们还是需要花一些功夫的