 菡萏如佳人
菡萏如佳人思维三十六计-产品篇(5)
需求价值度分析
Kano模型说明
kano模型是需求分析中经常会用到的模型,它是对产品期望与满意度之间的一个抽象。使用模型可以让我们思考时抹平用户个性化因素干扰,利用数据事实说话,找到众策下全局最优解。
一般当有多个需求需要排优先级的时候,我们还会在Kano基础上引入B-W四维分析法,所以将二者结合起来才能更好的帮助我们进行需求价值度分析。
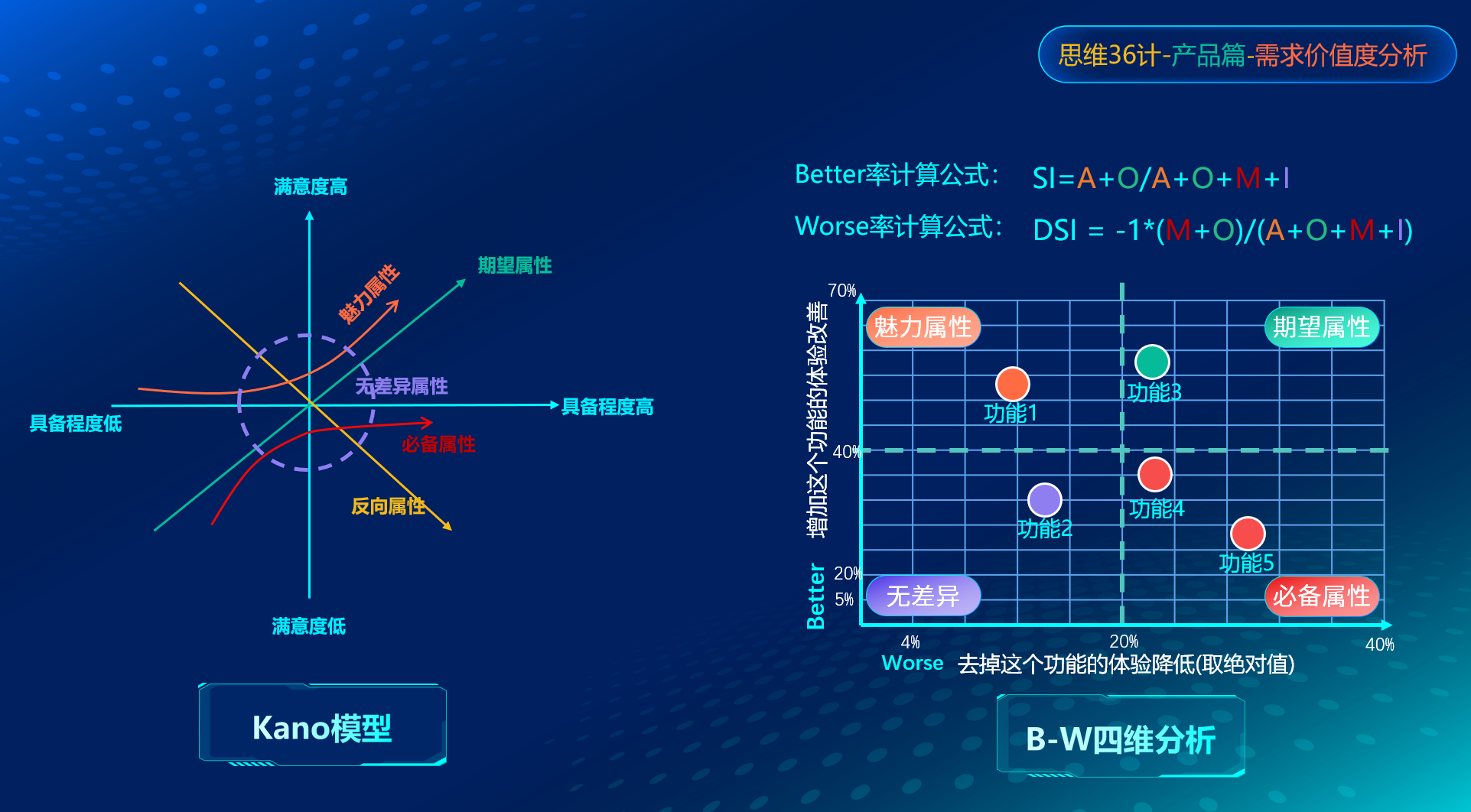
针对kano模型关键说明如下,B-W四维分析之后再进行讲解:
- 模型将产品功能进行了二维抽象,以满意度和具备程度作为横纵坐标,形成一个二维坐标系。
-
横坐标(x轴)代表产品功能的具备程度,越往右代表具备的程度越高。
-
纵坐标(y轴)代表产品的满意度,越往上代表越满意。
-
其中红色的曲线代表必备属性,表示用户认为该功能是产品必须要有的,比如一款微信的聊天功能,产品具备此项功能时,用户满意度不会提升,但不提供时用户满意度会立即下降。
-
其中绿色直线代表期望属性,表示用户期望产品是有该功能,所以提供时满意度会提升,不提供满意度会下降。
-
其中橙色的曲线代表魅力属性,表示用户出乎用户意料意外的功能,所以不提供的时候,满意度也不会降低,提供了用户满意度会大幅度上升。
-
其中白色的直线代表反向属性,表示用户根本没有此需求,所以你不提供时满意度不会变化,一旦提供了用户满意度反而会下降。
-
其中紫色圆形虚线代表无差异属性,表示无论提供与否,用户满意度不会发生变化。
初看起来kano模型非常简单易懂,但实际上kano是一个易学难精的模型。
每个公司都希望自己能够开发出属于魅力属性的产品,让用户满意度大幅度上升;然后不都愿意开发出属于反向属性的产品,主要是那些影响用户体验的功能。
然而这一些是是美好的幻想,随着一个产品的迭代发展与市场竞争,原来的那些魅力属性渐渐的会下沉为期望属性,而期望属性将会下沉为必备属性。周而复始,这是一个动态的过程。
还有公司产品的底层还是要构建在商业的基础上的,一个产品不可能总是以用户体验为先。比如说视频产品,用户体验最佳的情况当然是:想看什么片都有的看,也没有广告。
然而以爱优腾为代表的商业模式就是广告和会员,如果一个产品无法产生商业价值,那它就不可能存在。所以明知道广告功能是反向属性,你也得加,而且还得好好加。
kano应用分析
我们了解了kano图中各种属性的含义后,就可以开始做问卷调研了。我们以微信上视频号的功能为例子,拆解下如何使用kano模型来判断调研结果。
设计调查问题的时候,我们需要成对的进行设计,一面是正向的评价问题,另一面是负向的评价问题,如下所示:
问卷问题1:如果在微信上增加视频号功能,你的评价是?(正向)
A:我很喜欢 B:理应如此 C:无所谓 D:勉强接受 E:很不喜欢
问卷问题2:如果微信上没有视频号功能,你的评价是?(负向)
A:我很喜欢 B:理应如此 C:无所谓 D:勉强接受 E:很不喜欢
收集到用户成对的回答后,将两个问题的回答对照着映射到下方的表格中进行判断该功能对于此用户的属性是哪一个。
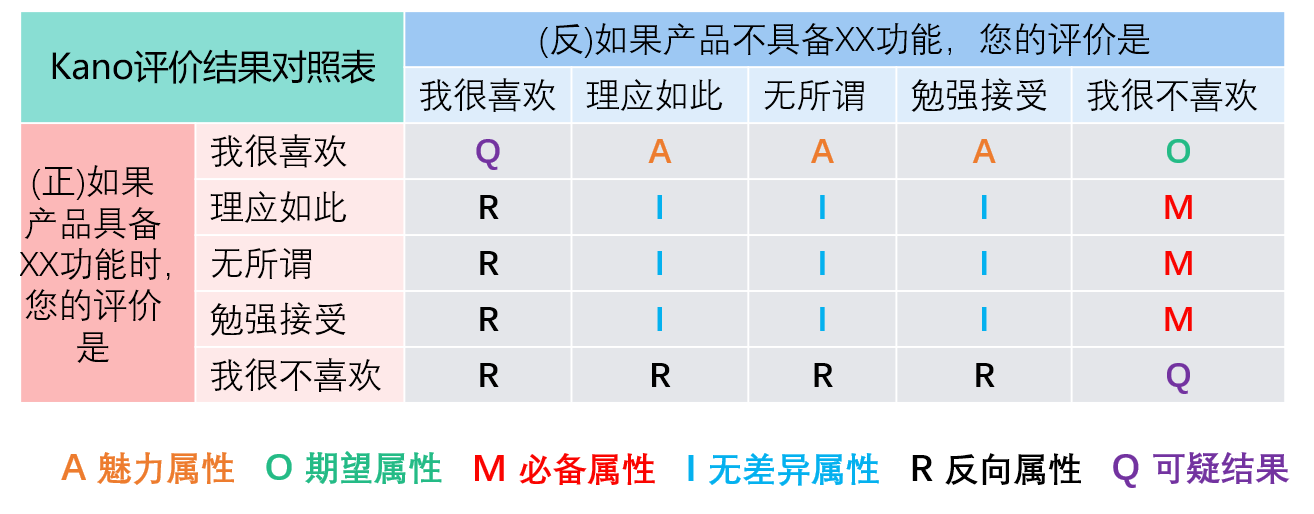
其中A表示魅力属性,O表示期望属性,M表示必备属性,I表示无差异属性,R表示反向属性,Q表示可疑结果,无效的问卷结果。
比如:用户第1个正向问题回答无所谓,第2个反向问题回答理应如此,映射到上表中就是I,表示该功能对于这个用户来说是无差异属性。
按照上述的方法,我们可以统计出最后问卷的结果里各个属性的数量,类似如下所示:
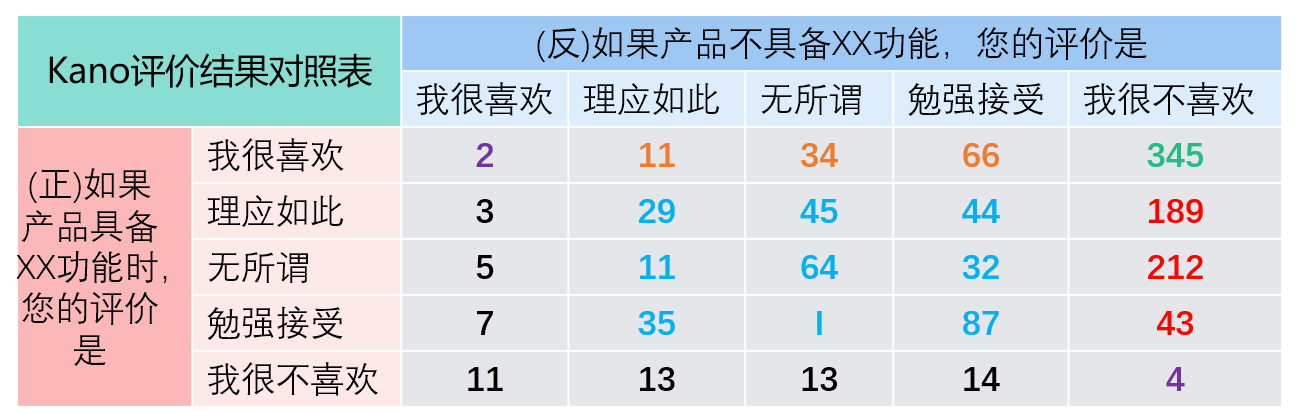
根据上表我们就可以统计出无差异属性的有多少,魅力属性的有多少。然后根据比例来决定产品里是否需要增加该功能。
这里需要额外说明的是调研的用户要做好选择,如果用户有明显的特征,可以还需要对不同群体进行分类统计。
上面就是对于产品中单个功能需求利用kano模型进行统计分析的方法,而当出现多个需求时,我们就需要再引入B-W模型,结合着kano一起来进行判断。
B-W思维系数
无论是大企业还是小企业,资源永远是不够用的,只能把资源用在最值得用的地方。所以当有多个需求需要排优先级的时候,我们就要引入B-W系数,来综合判断哪些需求应该最先安排,而哪些可能根本不需要做。
B-W系数就是Better-Worse率的计算,根据kano我们会得到各个属性的数量,我们需要根据下面的计算公式,计算出每个需求的Better率和Worse率。
- Better代表增加这个功能体验改善概率:SI = A+O/A+O+M+I
-
Worse去掉这个功能体验降低概率:DSI = -1*(M+O)/(A+O+M+I)
其中A表示魅力属性,O表示期望属性,M表示必备属性,I表示无差异属性,R表示反向属性,Q表示可疑结果。
按照公式求出多个需求的SI和DSI值。然后利用SI和DSI绝对值的平均值组成一个二维坐标系,共分为四象限。
假设我们有5个功能点,它们的计算的SI和DSI绝对值分别是:
功能1,SI:52% DSI绝对值:12%
功能2,SI:30% DSI绝对值:14%
功能3,SI:57% DSI绝对值:25%
功能4,SI:35% DSI绝对值:22%
功能5,SI:23% DSI绝对值:30%
根据上述结果计算得到纵坐标SI平均值大约:40%,横坐标DSI绝对平均值大约:20%。我们以40%和20%分别作为横纵坐标的中心线,可以绘制出如下图所示的二维坐标系:
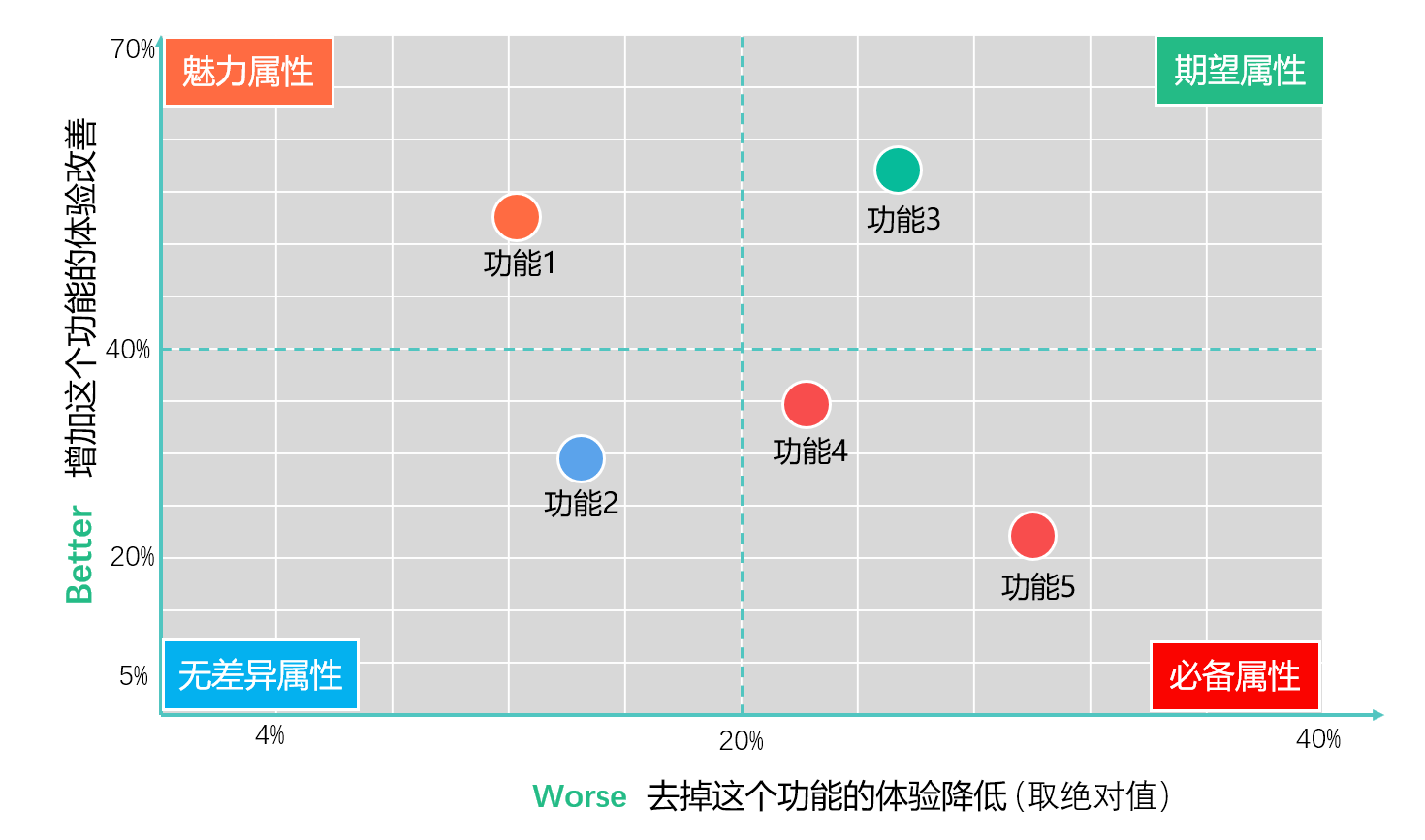
然后把各个功能点以(SI,|DSI|)为坐标点,绘制到坐标系中。根据我们示例数据,5个功能点的分布如上图所示。
第1象限代表期望属性,第2象限代表魅力属性,第3象限代表无差异属性,第4象限代表必备属性。资源分配原则先保证必备象限的功能,再保证期望象限功能,最后保证魅力象限功能,无差异象限功能不做。
所以最后优先开发功能4和功能5,如果资源只能选其中一个。我们选择Better值更高的功能4。必备区功能开发完毕后,再是开发功能3,然后是功能1。而功能2不需要开发。
以上就是kano模型结合B-W系数,计算多个需求优先级的方法。