 菡萏如佳人
菡萏如佳人文章目录
DDD领域驱动战略篇(2)
领域知识
软件开发团队的沟通与协作
- 组建好项目团队的第一件事:先识别问题域,进而为团队提炼达成共识的领域知识
- 我们需要把需求看成一颗种子,技术人员要和领域专家一起共用培育
- 在先启阶段,与提炼领域知识相关的活动有:
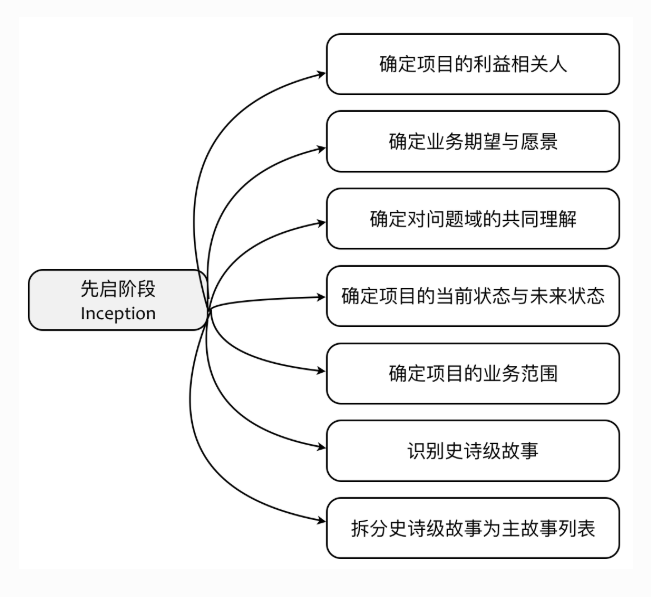
- 每个活动是有顺序关系的,从上到下
- 迭代开发阶段,针对迭代生命周期和用户故事生命周期可以开展不同形式的沟通与协作
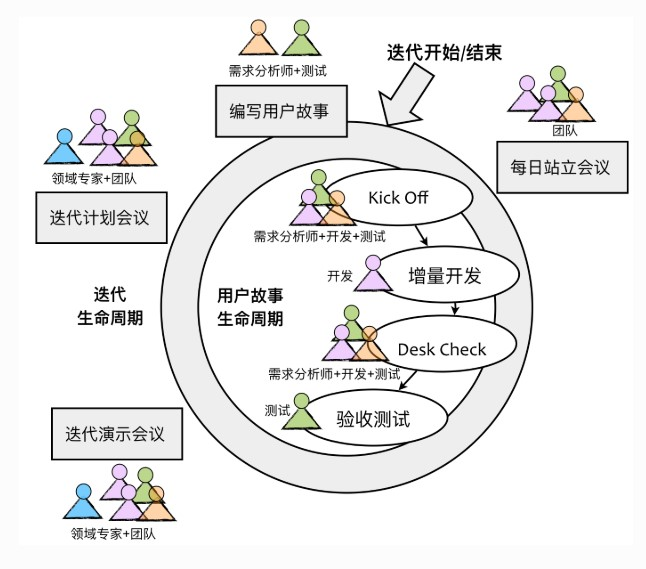
- 领域专家:介绍和解释该迭代需要完成的用户故事,包括用户故事的业务逻辑与验收标准
- 开发人员:使用工时卡对用户故事进行评估,预估故事耗时
- 项目经理:每天了解当前的迭代进度,并与产品负责人一起基于当前进度和迭代目标确定是否需要调整需求的优先级
- 测试人员:迭代完成后需要召开演示会议进行功能演示,可以邀请实际客户参与
- 用户故事指导着开发人员的开发、测试人员的测试,它是构成领域知识的最基本单元
- 敏捷开发实践强调业务分析人员与测试人员共同编写验收测试的自动化测试脚本
- 时刻牢记未经过测试用户故事价值为0
运用场景分析提炼领域知识
领域场景分析方法6W模型
- 一种生动的方式是通过“场景”来展现领域逻辑
- 组成场景的要素常常被称之为 6W 模型,即描写场景的过程必须包含 Who、What、Why、Where、When 与 How 这六个要素
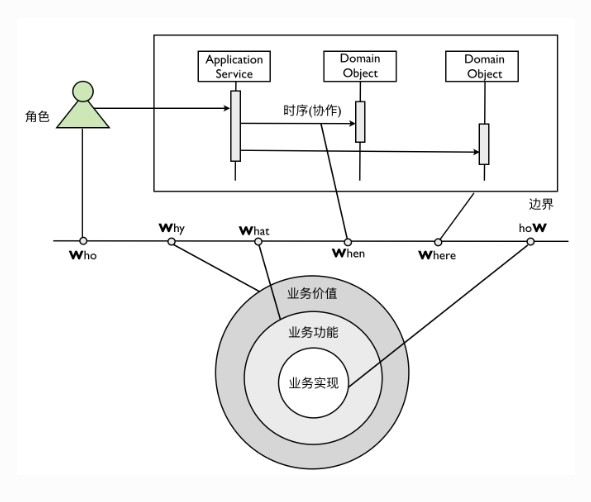
首先需要识别参与该场景的用户角色(Who),通过分析该用户的特征与属性来辨别该角色在整个场景中参与的活动
这意味着我们需要明确业务功能(What),思考这一功能给该角色能够带来什么样的业务价值(Why)
- 领域功能划分为三个层次,即业务价值(Why)、业务功能(What)和业务实现(How)
领域场景分析方法
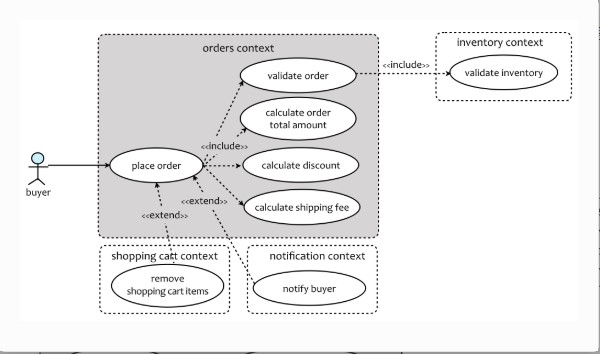
- 用例:每个用例都是系统中一个完整序列的事件(下图是一个下订单的用例示例)

转换成图形:
- 用户故事:敏捷开发中的需求功能点,每次迭代由不同的用户故事组成,一个用户故事就是一个独立的业务场景
用户故事的典型模板:

不合格的用户故事:作为一名用户,我希望可以提供查询功能,以便于了解分配我的任务情况
合格的用户故事:作为一名普通项目成员,我希望获取分配给自己的未完成任务,以便于跟踪自己的工作进度 -
需求分析人员与测试人员结对编写用户故事,一个完整的用户故事必须是可测试的,有验收标准的
注意:用户故事应该只受到业务规则与业务流程变化的影响,不要考虑任何UI操作 -
测试驱动开发:测试先行,先写测试用例,然后将一个个测试用例跑通
建立统一语言
- 获得统一语言就是需求分析的过程,也是团队中各个角色就系统目标、范围与具体功能达成一致的过程
- 统一语言的体现:统一的领域术语,统一的领域行为描述
- 在维护领域术语表时,一定需要给出对应的英文术语,否则可能直接影响到代码实现
- 领域行为是对业务过程的描述,相对于领域术语而言,它体现了更加完整的业务需求以及复杂的业务规则
- 领域行为注意点:强调动词的精确性,符合业务动作在该领域的合理性;要突出与领域行为有关的领域概念
磨刀不误砍柴工,多花一些时间去打磨统一语言,并非时间的浪费,相反还能改进领域模型乃至编码实现的质量,反过来,领域模型与实现的代码又能避免统一语言的“腐化”,保持语言的常新。重视统一语言,就能促成彼此正面影响的良性循环;否则领域模型与代码会因为沟通不明而泥足深陷,就真是得不偿失了。
限界上下文
理解限界上下文
限界上下文定义
什么是限界上下文(Bounded Context)?让我们来读一个句子:wǒ yǒu kuài dì
到底是:我有快递还是我有块地?如果没有说话的语境上下文,我们确定不了!当我们在理解系统的领域需求时,同样需要借助这样的上下文,而限界上下文的含义就是用一个清晰可见的边界(Bounded)将这个上下文勾勒出来,如此就能在自己的边界内维持领域模型的一致性与完整性。
在实际的业务场景中,不同的上下文,同一个人扮演的角色可能是不同的,如下图所示:
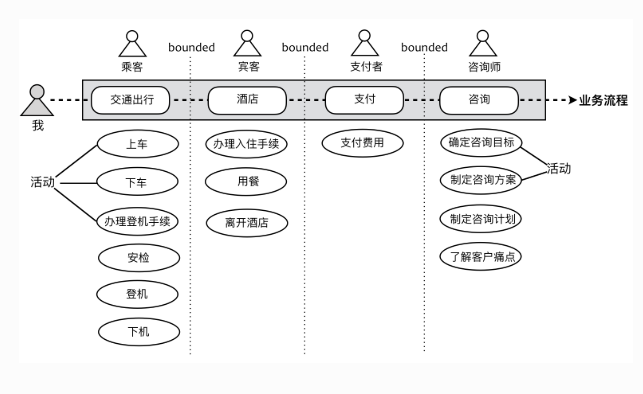
理解限界上下文时,要注意的几个关键点:
- 知识:不同上下文领域知识不同,如果在一个上下文里某活动不具备对应知识,则活动分配不合理
- 角色:深入思考参与到一个上下文中对象到底是什么角色,以及角色之间是如何协作的
- 边界:按照不同关注点进行划分,越是关系弱,越是要划定边界
限界上下文价值
- 领域逻辑层面:限界上下文确定了领域模型的业务边界,维护了模型的完整性与一致性,从而降低系统的业务复杂度
- 团队合作层面:限界上下文确定了开发团队的工作边界,建立了团队之间的合作模式,避免团队之间的沟通变得混乱,从而降低系统的管理复杂度
- 技术实现层面:限界上下文确定了系统架构的应用边界,保证了系统层和上下文领域层各自的一致性,建立了上下文之间的集成方式,从而降低系统的技术复杂度
- 限界上下文本质:并不是像大多数程序员理解的那样,是模块、服务、组件或者子系统,而是你对领域模型、团队合作以及技术风险的控制
- 醍醐灌顶:限界上下文目的不仅仅是为了划分边界,更是为了如何控制边界
限界上下文是“分而治之”架构原则的体现,我们引入它的目的其实为了控制(应对)软件的复杂度,它并非某种固定的设计单元,它可以成为系统、模块、服务或组件
理解限界上下文的三种境界:
- 1 参悟之初:模块、服务或组件就是限界上下文(看山是山,看水是水)
- 2 当有悟时:模块、服务或组件不是限界上下文(看山不是山,看水不是水)
- 3 彻底悟透:模块、服务或组件仍然是限界上下文(看山仍然山,看水仍然是水)
限界上下文自治特点
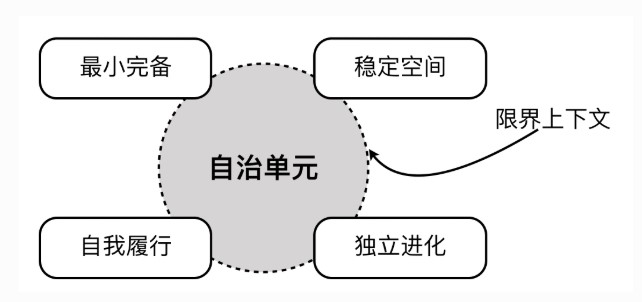
- 最小完备:根据业务价值的完整性进行设计,无需针对自己的信息去求助别的自治单元,这就避免了不必要的依赖关系
- 稳定空间:减少外界变化对限界上下文内部的影响,符合OCP原则
- 自我履行:自治单元自身决定要做什么,履行的职责一定是你掌握的知识范畴之内
- 独立进化:减少限界上下文的变化对外界的影响,需要接口设计良好,符合标准规范,并在版本上考虑了兼容与演化
这四个要素又是高内聚低耦合思想的体现。我们需要根据业务关注点和技术关注点,尽可能将强相关性的内容放到同一个限界上下文中,同时降低限界上下文之间的耦合。对于整个系统架构而言,不同的限界上下文可以采用不同的架构风格与技术决策,而在每个限界上下文内部保持自己的技术独立性与一致性。
限界上下文控制力
限界上下文分离了业务边界
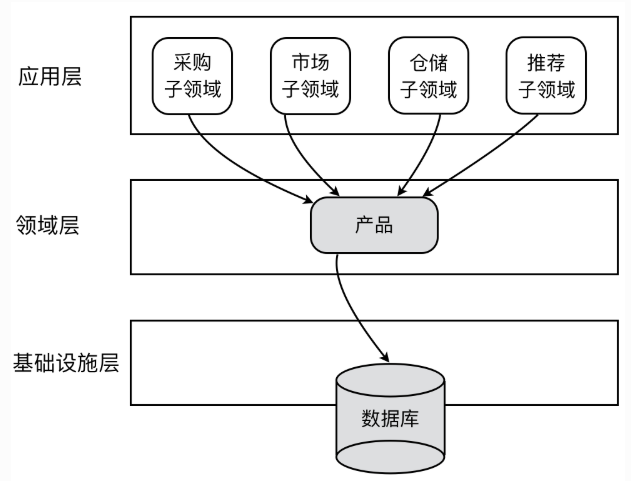
一个不好的示例:产品领域对象被多个子领域使用,但是每个子领域关心产品领域中的属性和行为却不相同,这将导致领域模型和数据模型耦合,违背了SRP原则,产品类变成了一个上帝类
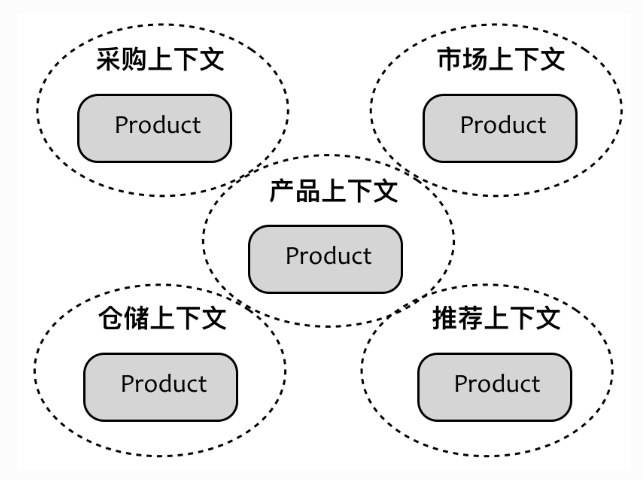
正确的示例:虽然不同的限界上下文都存在相同的 Product 领域模型,但由于有了限界上下文作为边界,使得我们在理解领域模型时,是基于当前所在的上下文作为概念语境的。这样的设计既保证了限界上下文之间的松散耦合,又能够维持限界上下文各自领域模型的一致性,此时的限界上下文成为了保障领域模型不受污染的边界屏障。
限界上下文明确了工作边界
根据亚马逊公司提出的2PTs 规则,团队成员人数控制在 7~10 人左右比较合适
2PTs 规则自有其科学依据。如果我们将人与人之间的沟通视为一个“联结(link)”,则联结的数量遵守如下公式,其中 n 为团队的人数:
N(link) = n*(n-1)/2
联结的数量直接决定了沟通的成本,以 6 人团队来计算,联结的数量为 15;12人团队,则联结数陡增至 66;50人团队,联结数竟然达到了惊人的 1225
矩阵式组织结构,特性(项目)团队和组件(职能)团队

我们按照领域特性来组建团队,使得团队成员之间的沟通更加顺畅,至少针对一个领域而言,知识在整个特性团队都是共享的。二者的结合可以取长补短。
限界上下文封装了应用边界
从控制技术复杂度的角度来考虑技术实现,从而做出对系统质量属性的响应与承诺,通常体现在如下几个方面:
- 高并发(临时性流量高峰的场景)
- 功能重用(用户权限管理之类)
- 实时性(大数据下的更新)
- 第三方服务集成(支付,安全)
- 遗留系统(整体作为一个上下文)
识别限界上下文
限界上下文的识别并不是一蹴而就的,需要演化和迭代。通过从业务边界到工作边界再到应用边界这三个层次抽丝剥茧,分别以不同的视角、不同的角色协作来运用对应的设计原则,会是一个可行的识别限界上下文的过程方法。
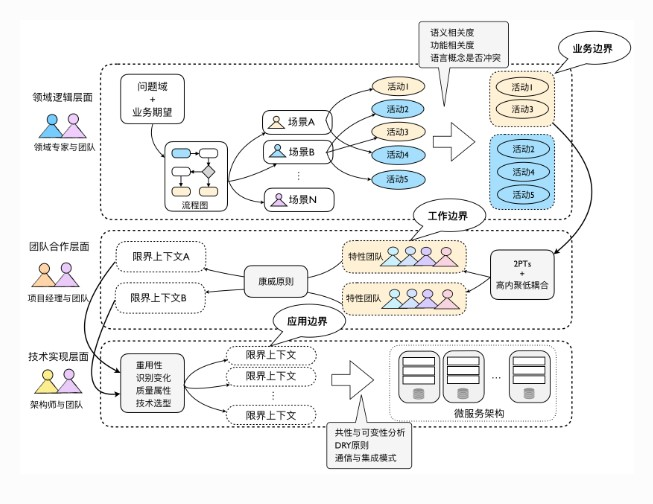
从业务边界识别
- 对业务流程进行梳理,划分出业务场景
- 从业务场景中识别业务活动(动宾结构)
- 将业务活动根据语义相关性(包含同一个领域对象)和功能相关性(依赖关联关系)进行归类
- 将识别出来的归类进行业务边界命名,命名的难易也是有效判断划分准确与否的一个标准
从工作边界识别
- 根据团队人数,一般一个团队至多负责一个上下文
- 根据预估工作量,当一个限界上下文工作量过大,就要考虑拆分了
- “任劳任怨”的好团队也不是真正的好团队,边界内的要积极,边界外的要“抱有成见”
从应用边界识别
- 关注系统的质量属性,不同质量属性要求的可以考虑划分成不同的限界上下文
- 考虑重用和变化,可重用的部分作为独立的上下文,不同变化维度的划分为不同限界上下文