 菡萏如佳人
菡萏如佳人API网关Zuul
根据我们前几章介绍的SpringCloud微服务组件已经可以搭建一个功能比较完善的服务架构了,如下图所示:

使用Eureka的集群实现高可用的服务注册中心,各服务间的负载均衡使用Ribbon或Feign来包装实现,
对于依赖的服务调用使用Hystrix来进行包装,实现线程隔离并加入熔断机制,避免服务的雪崩效应。
微服务A可以看做是对外的服务,通常也称之为边缘服务,它的负载一般是通过软负载或者硬负载来实现。
看起来一切都似乎很不错,而且我们可以保证,上面的系统架构的确是没有问题的。但是是否存在不完美的地方呢?
我们可以从二个角度来看看:
- 开发人员:一般情况下,对外的服务部分应该需要考虑一些安全性。所以我们肯定会在A服务访问中加入一些权限的校验机制,比如校验用户登录状态,token令牌等。要注意的是我们采用的是分布式部署,A服务背后依赖的所有服务,我们可能都要加入这些校验逻辑,假设新增一个C服务,那么A服务就要改造,下次新增一个D服务,A服务又要改造;而且A服务的改造影响范围是巨大的,完全背离了设计准则中的开闭原则。还有一个是随着服务的增加,A服务的校验逻辑也将越来越复杂,不仅增加了开发难度,每次测试工作量也越来越大。
-
运维人员:我们可以看到A服务的负载是由nginx这类软负载或者F5这类硬负载实现的,运维人员必须人工的维护这种路由规则对应的服务实例列表。当有实例发生增减或者IP地址(使用域名可以避免这个问题)变动的时候,也需要手工去同步修改这些信息,保证实例信息与中间件配置的一致性。当系统规模不大时,这个工作量可能还好,一旦系统规模到达3位数,人工维护将变得非常困难,很容易出错。
所以为了解决上面的问题,使得我们的微服务架构更加完美,就需要引入API网关Zuul。
基本介绍
API网关类似设计模式中的Facade(门面)模式,所有的外部客户端访问都需要经过它来进行调度和过滤。它负责实现请求路由、负载均衡、校验过滤、请求转发熔断机制、服务聚合等功能。在SpringCloud的微服务中,API网关的解决方案是Zuul。它作为一个服务注册到Eureka注册中心中,这样就可以获取注册中心的其他微服务实例,从未实现了对路由规则与服务实例维护问题;Zuul提供了一套过滤器的机制,开发者可以利用过滤器机制做一些过滤,拦截和校验工作,大大降低了开发难度。
快速入门演示
我们接下来会搭建一个简单的网关应用,架构中会用到我们之前的一些项目模块,我们知道在springCloud微服务系统中,客户端是既可以作为消费者又可以作为生产者的。所以大家不用关心各个功能间的调用关系,只要把它们看成都是网关服务的提供者就可以了。整体架构如下:

- 构建网关Zuul
第一步:引入依赖
compile('org.springframework.cloud:spring-cloud-starter-zuul')
我们观察下这个依赖包装了哪些依赖:
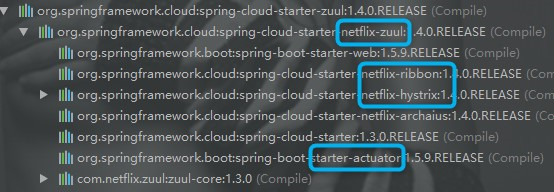
我们可以发现,SpringCloud的zuul是对Netflix-zuul做了封装,还加入了负载均衡Ribbon,熔断保护Hystrix,springboot中的端点管理actuator。
第二步:开启注解,使用@EnableZuulProxy开启Zuul的API网关功能
@EnableZuulProxy
@EnableEurekaClient
@SpringBootApplication
public class ServiceZuulApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceZuulApplication.class, args);
}
}
第三步:增加配置
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 8769
spring:
application:
name: service-zuul
zuul:
routes:
api-a:
path: /api-a/**
serviceId: service-ribbon
api-b:
path: /api-b/**
serviceId: service-feign
配置的时候我们可以使用url的方式,具体指定某个URL地址对应的实例,但是不推荐,我们应该采用面向服务的路由配置方式,通过serviceId配置服务。
注意:采用URL配置实例的方式是不会使用HystrixCommand进行包装的,所以就丧失了线程隔离和断路器保护,负载均衡的能力。
- 请求过滤:之前说过,网关是要负责权限校验等操作的,这里为了演示方便就做了简单的token验证
@Component
public class MyFilter extends ZuulFilter{
private static Logger log = LoggerFactory.getLogger(MyFilter.class);
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
log.info(String.format("%s >>> %s", request.getMethod(), request.getRequestURL().toString()));
Object accessToken = request.getParameter("token");
if(accessToken == null) {
log.warn("token is empty");
ctx.setSendZuulResponse(false);
ctx.setResponseStatusCode(401);
try {
ctx.getResponse().getWriter().write("token is empty");
}catch (Exception e){}
return null;
}
log.info("ok");
return null;
}
}
关于过滤器的知识,在文章后面会有详解,这里大家只要知道我们可以通过继承ZuulFilter来实现自定义的过滤器。四个方法定义如下:
- filterType:过滤器类型,决定过滤器在请求的哪个生命周期执行,pre代表在路由之前
- filterOrder:过滤器执行顺序,根据其返回值决定执行顺序
- shouldFilter:是否需要被执行
- run:过滤器的具体执行逻辑
启动各个服务:所有服务清单如下
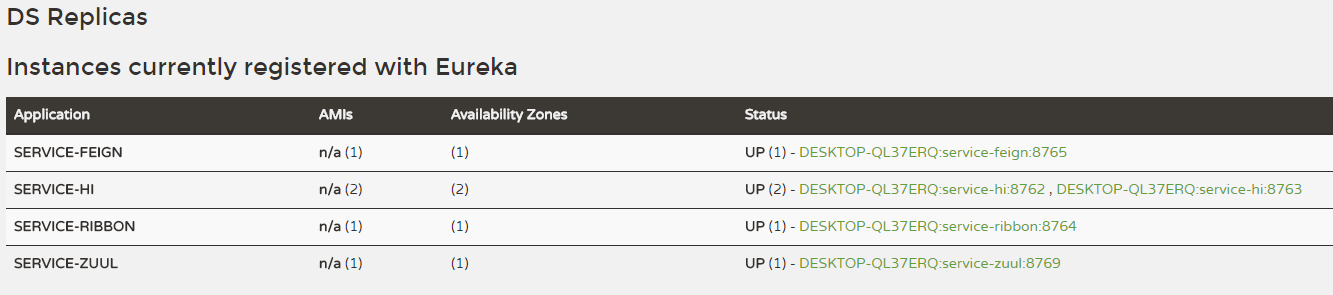
注意:8763服务是包含了随机睡眠时间的,所以调用的时候会超时报错
- 输入测试
通过Ribbon访问服务的URL:localhost:8769/api-a/hi?name=hzqiuxm&token=qiuxm
通过Feign访问服务的URL:localhost:8769/api-b/hi?name=hzqiuxm&token=qiuxm
上面两个URL可能返回的结果:
hi hzqiuxm, i am from port8762
{
"timestamp": 1525409450143,
"status": 500,
"error": "Internal Server Error",
"exception": "com.netflix.zuul.exception.ZuulException",
"message": "GENERAL"
}
hi hzqiuxm, i am from port8763
hi hzqiuxm, i am from port8762
当URL中不包含token的时候,不会发生调用,网关就直接返回:token is empty
通过简单的示例,我们现在可以理解API网关带来的好处:
1 作为系统统一入口,屏蔽了系统内部各个微服务的调用细节
2 可以与服务治理框架结合,可以实现自动化的实例维护、负载均衡、路由转发。
3 可以实现权限校验与业务逻辑的解耦
4 保证了微服务无状态,易于扩展和测试
5 通过配置实现路由规则,易于测试维护
路由详解
在上面的简单示例中提及,我们要以面向服务方式来配置理由规则。接下来就讲讲路由配置的一些匹配规则个配置要点。
服务路由配置
对于面向服务的路由配置,我们可以采用上面配置中path和serviceId映射配置方式外,还可以采用一种更简洁的方式:zuul.routes.
zuul:
routes:
service-ribbon: /api-a/**
相信大家都有一个疑问,我们只配置了服务名称,那zuul网关接收到外部请求,是如何解析并转发到服务的具体实例上的呢?其实在前面已经埋下了伏笔,我们引入依赖的时候特地观察了下zuul所封装的依赖,里面就包含了ribbon。zuul会从注册中心获取所有服务以及它们的实例清单,所以在Eureka的帮助下,网关本身就已经维护了serviceId与实例地址的映射关系。它会根据Ribbon负载策略选择一个具体的实例进行转发,从而完成路由的工作。
服务路由的默认规则
在Zuul构建网关中引入Eureka后,它会为每个服务都自动创建一个默认的路由规则,这些路由规则的path就是使用serviceId配置的服务名作为请求前缀的。
例如:zuul.routes.service-ribbon.serviceId=user-service服务的默认路由规则就是zuul.routes.service-ribbin.path=/user-serviceId/**,所以当你的服务中心有一个service-ribbon服务的时候。上面这两个配置映射就是默认存在的。
默认有时候是比较方便,但是如果我们不希望zuul自动创建类似上面的映射关系的话,我们可以使用zuul.ignored-services参数来设置一个服务名表达式来定义不进行自动创建。
比如:zuul.ignored-services =* 禁止对所有服务自动创建路由规则。
自定义路由映射规则
通过默认规则我们知道,zuul默认生成的path和以serviceId为前缀的,但是如果我们的服务类似带有版本号的,比如:userservice-v1,如果是默认的,那么对应的path就是/userservuce-v1,熟悉REST风格的开发人员知道,一般带有版本号的url是这样的:/v1/userservice/,如果要满足这个需求,我们就要自定义路由映射规则了。步骤也很简单,只要网关程序中增加一个Bean即可:
@Bean
public PatternServiceRouteMapper serviceRouteMapper(){
return new PatternServiceRouteMapper(
"(?<name>^.+)-(?<version>v.+$)",
"${version}/${name}");
}
PatternServiceRouteMapper对象可以通过正则表达式方式来自定义服务与路由映射关系,当匹配不上时,还是会使用默认的路由规则的。
路径匹配
路由匹配路径的表达式,我们可以采用通配符的方式:
? :匹配任意单个字符
* :匹配任意数量的字符
** : 匹配任意数量的字符,支持多级目录
那它们的优先顺序是怎么保证的呢?路由的规则加载算法是通过LinkedHashMap来保存的,说明规则保存是有序的,但是内容的加载是通过线性遍历配置文件来依次加入的。
所以我们要注意properties的配置内容无法保证有序,YAML的文件可以保证有序。
除此之外我们还可以通过zuul.ignored-patterns设置让API网关忽略的URL表达式;可以通过zuul.prefix全局为路由增加前缀信息;使用forward来进行本地跳转
Cookies与头信息
在默认情况下,Zuul会过滤掉HTTP请求头中的一些敏感信息,默认的敏感头信息通过zuul.sensitiveHeaders参数定义。cookies默认在网关中是不会传递的,所以当我们使用了Spring Security、Shiro等安全框架构建路由时,由于cookies无法传递,web应用将无法鉴权。我们有二种方式可以解决:
- 全面覆盖:设置一个空值,覆盖掉原来的默认值(不推荐)
zuul.sensitiveHeaders=
- 指定路由的参数配置:方式有二种(推荐)
zuul.routes.<router>.customSensitiveHeaders=true //对指定的路由开启自定义敏感头
或者
zuul.routes.<router>.sensitiveHeaders= //将指定路由的敏感头设置为空
断路保护与负载
在上面我们就提到,采用URL配置实例的方式是不会使用HystrixCommand进行包装的,所以就丧失了线程隔离和断路器保护,负载均衡的能力。所以我们应该都采用面向服务的方式来进行配置。我们也可以通过Hystrix和Ribbon的参数来调整路由请求的各种超时时间。
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds //执行超时时间
ribbon.ConnectTimeout //路由转发请求时,创建请求连接的超时时间,应该小于断路器超时时间
ribbon.ReadTimeout //路由转发请求的超时时间,也应该小于断路器超时时间
zuul.retryable = false //全局关闭自动重试机制
zuul.routes.<route>.retryable = false //指定路由关闭自动重试机制
过滤器详解
过滤器简介
过滤器是Zuul中的核心,一个Zuul网关主要就是对请求进行路由和过滤。路由功能负责将外部请求转发到具体的微服务实例上,过滤功能负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。实际上路由转发也是通过过滤器来完成的。每一个进入Zuul的HTTP请求都会经过一系列的过滤器处理链得到请求响应并返回客户端的。
Zuul过滤器必须包含4个基本特征:过滤类型、执行顺序、执行条件、具体操作。在之前的示例中我们已经看到过,其实它们就是ZuulFilter抽象类和IZuulFilter接口定义的抽象方法:
boolean shouldFilter();
Object run();
abstract public String filterType();
abstract public int filterOrder();
- shouldFilrer:是否要执行该过滤器
- run:过滤器的具体逻辑,我们可以实现自定义的逻辑
- filterType:过滤器类型
pre: 在请求被路由之前调用
routing:在路由请求时调用
post:在routing和error之后调用
error:处理请求发生错误时调用 - filterOrder:过滤器执行顺序,数值越小优先级越高
下面是一个请求在各个过滤器中生命周期:
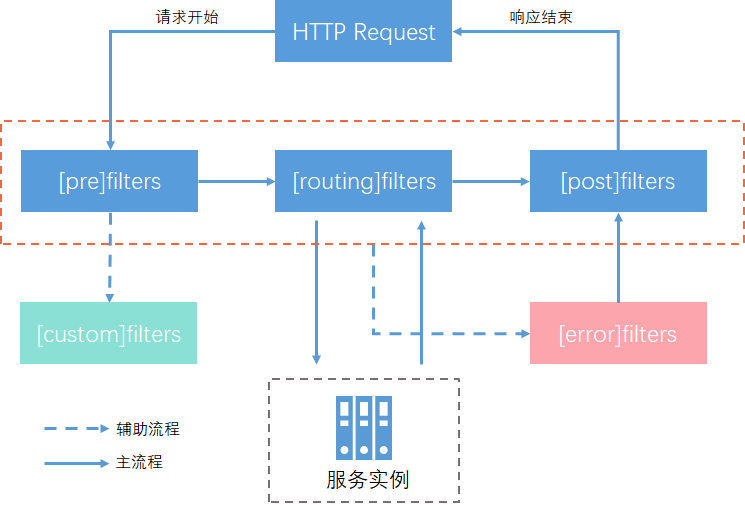
- 外部请求过来时,首先进入第一个阶段pre,主要是对路由前的请求做一些前置加工,比如:请求校验。
- 完成pre类过滤器处理后,请求进入第二个阶段:routing,该阶段是路由转发阶段,将请求转发到具体的服务实例的过程,当服务实例将请求结果返回之后,该阶段完成、
- 完成routing后,进入第三个阶段:post,该阶段不仅可以获取到请求信息,还可以获取到服务实例的返回信息。所以可以对结果进行加工转换后返回给客户端
- error是一个特殊阶段,在上述三个阶段中发生异常时就会触发,但是要注意,它最后是流向post阶段的,因为post才能将结果返回给客户端。
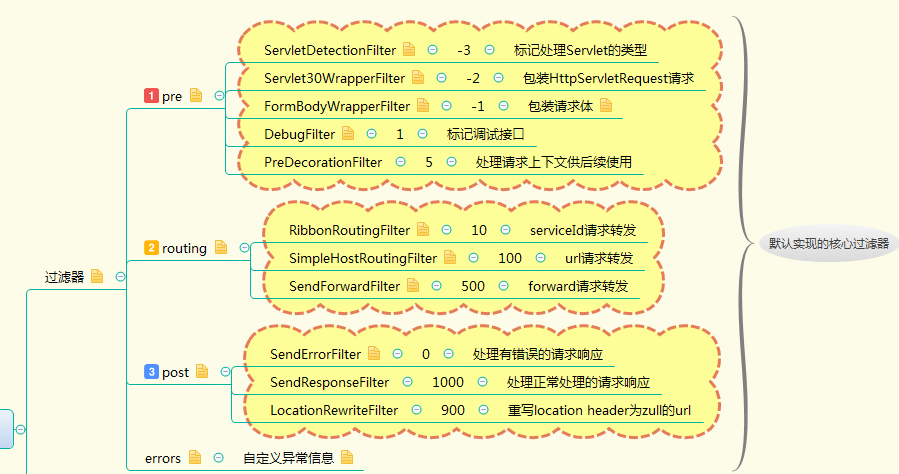
核心过滤器
下面对上面提到的几个过滤器,我们详细了解下,有助于我们更好的理解Zuul以及自定义自己业务逻辑。
我们可以前往org.springframework.cloud.netflix.zuul.filters包下查看每种过滤器类型下包含的过滤器。
pre过滤器
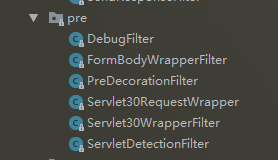
- ServletDetectionFilter,执行顺序-3,是最先被执行的过滤器。用来检测请求是否是通过Spring的DispatcherServlet处理运行的。
一般情况下,发送到API网关的外部请求都是通过Spring的DispatcherServlet处理的。
除了通过/zuul/*路径访问的请求,会绕过DispatcherServlet,被ZuulServlet处理,主要是用来处理大文件的上传,这个路径可以通过zuul.servletpath参数进行配置。 -
Servlet30WrapperFilter,执行顺序-2,是第二个执行的过滤器。目前对所有请求生效,主要将原始HttpServletRequest包装成为Servlet30RequestWrapper对象。
-
FormBodyWrapperFilter,执行顺序-1,是第三个执行的过滤器。主要目的讲符合要求的请求体包装成FormBodyRequestWrapper对象。它只对两类请求生效,通过ContentType判断:
1.application/x-www-from-urlencoded(会将表单内的数据转换为键值对)
2.multipart/form-data(既可以上传文件,也可以上传键值对,它采用了键值对的方式,所以可以上传多个文件。)且是 DispatcherServlet处理的 - DebugFilter,执行顺序是1,是第四个执行的过滤器。主要提供debug信息,辅助分析问题。
- PreDecorationFilter,执行顺序是5,是pre阶段最后执行的过滤器。主要是根据上下文参数对请求进行预处理。
routing过滤器

- RibbonRoutingFilter,执行顺序10,是route阶段第一个执行的过滤器。只对请求上下文中有serviceId参数的请求进行处理,换句话说就是只对面向服务的配置生效。主要目的是进行请求转发。
-
SimpleHostRoutingFilter,执行顺序100,是route阶段第二个执行的过滤器。只对url配置路由规则生效,一般不建议这么配置,因为不具备线程隔离和断路器功能。
-
SendForwardFilter,执行顺序500,是route阶段第三个执行的过滤器。只处理请求上下文中存在forward.to参数的请求,处理路由规则中forward本地跳转配置。
post过滤器
- SendErrorFilter,执行顺序0,是post阶段第一个执行的过滤器。需要请求上下中,要有error.status_code参数,所以在自己设置的异常中要设置该参数。主要是用来处理有错误的请求响应。
-
LocationRewriteFilter,执行顺序900。主要目的将location头重写为zuul的URL。
-
SendResponseFilter,执行顺序1000,是post阶段最后一个执行的过滤器。主要目的是利用上下文的响应信息来组织需要发送各个客户端的响应内容。
异常处理
自定义实现继承ZuulFilter类,对自定义过滤器中处理异常的两种解决方法:
1 通过在阶段过滤器中增加try-catch块,实现内部异常处理。注意一定要设置error.status.code参数才会被SendErrorFilter处理,该种方式是对开发人员基本要求。
2 利用自定义的ErrorFilter类处理,利用error类型过滤器的生命周期特点,集中处理其它几个阶段抛出的异常信息。继承ZuulFilter过滤器,指定为error类型,在run()方法中也要设置error.status.code。该种方式作为第一种方式的补充,防止意外情况发生。
error过滤器问题
前面3个阶段出错时,都会走到这个过滤器中。但是最后错误参数起作用的关键是在post阶段的SendErrorFilter过滤器里,所以在error处理之后,还要进入到post的处理阶段才能生效,但是post阶段本身出错后,是不会进入post阶段的。
解决方案:
1 直接实现error过滤器时,组织实现(不推荐,这样错误返回代码会有多处)
2 依然交给SendErrorFilter来处理(继承SendErrorFilter类,复用run方法,重写类型,执行顺序要大于SendErrorFilter,执行条件里只执行post阶段产生的异常即可,要做到判断哪个阶段的异常,需要对过滤器的核心处理器FilterProcessor进行扩展,实现自定义的过滤器处理器,并记录下该信息)
注意:要使扩展的过滤器处理类生效,需要调用FilterProcessor.setProcessor(新的过滤器处理器)方法来启动。
自定义异常信息
默认的错误信息一般并不符合系统设计的响应格式,所以我们要对返回的异常信息进行定制。
自定义异常信息两种方法:
1 编写一个自定义的post过滤器(类似重写SendErrorFilter实现),自己组织响应结果
2 不采用重写方式,可以对/error端点实现,通过自定义实现一个错误属性类覆盖默认的ErrorAttribute.class
下图是对核心过滤器主要信息的一个汇总思维导图:
核心处理器与禁用过滤器
FilterProcessor负责管理和执行各种过滤器,自定义的过滤器处理器,需要设置后才能生效,通过setProcessor()方法来设置。
Zuul.<SimpleClassName过滤器类型>.<FilterType过滤器类型>.disable=true来进行设置禁用某个过滤器
例子:zuul.AccessFilter.pre.disable=true
动态加载
我们可以动态修改路由规则,动态添加和删除过滤器。
动态路由
这个需要依赖下一章节中介绍的配置中心来实现,通过配置中心,类似配置文件动态刷新。
动态过滤器
本身过滤是通过编码实现的,我们可以借助JVM实现的动态语言,比如Groovy来实现。
目前应该还是一个半成品,处理一些简单的过滤功能,应该没有问题,目前还是不要大规模的进行使用。
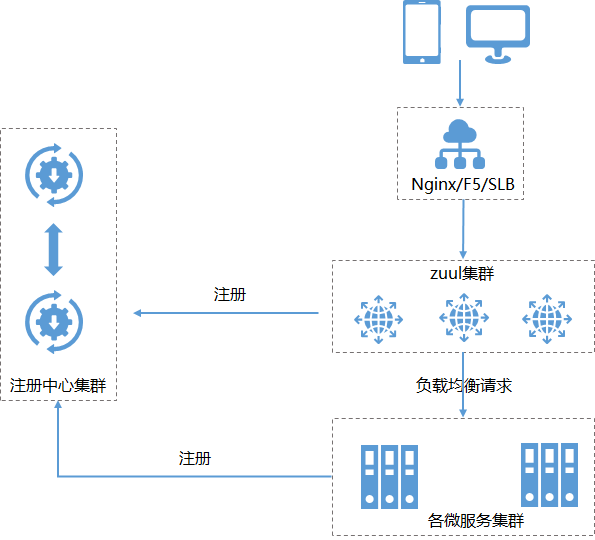
网关的高可用
网关的高可用一般由二种方式:
一种是网关客户端不注册到注册中心,比较多的服务网关就是直接提供给外部调用的,所以采用这种方式,架构图如下:
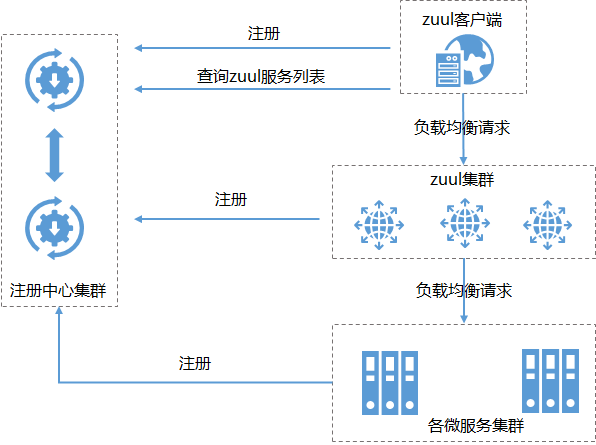
一种是网关客户端也注册到注册中心,这样就不需要额外的软负载或者硬负载了,直接都由客户端负载来实现,架构如下:
网关小结
- Zuul网关路由规则的配置要采用面向服务的配置,学习了配置中心后,我们就可以实现动态路由了
- 掌握请求在网关中的生命周期
- 了解Zuul网关中的核心过滤器
- 掌握自定义各种类型的过滤器满足实际业务场景需求
- 掌握自定义异常处理的两种方法
- 掌握自定义异常信息的两种该方法
- 掌握自定义过滤器处理器定义
- 掌握网关的高可用架构设置