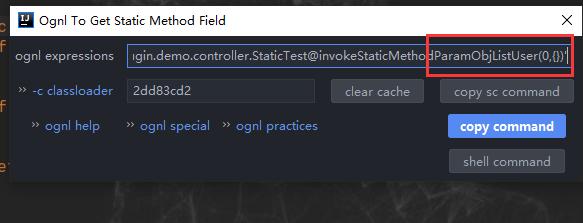
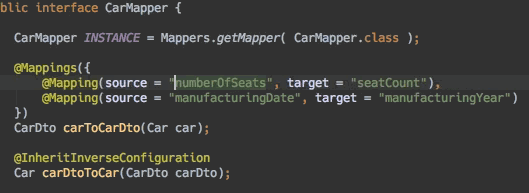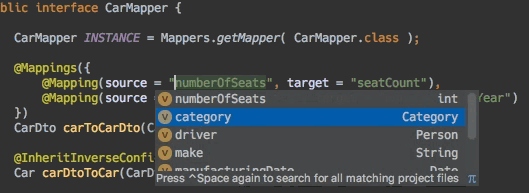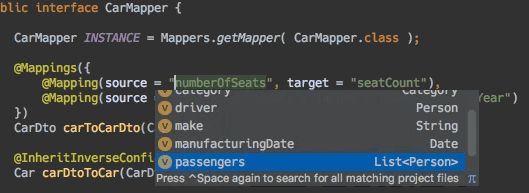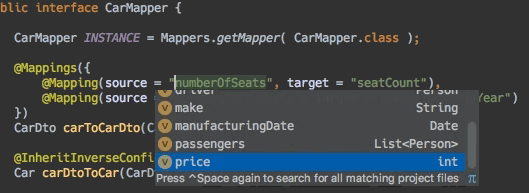
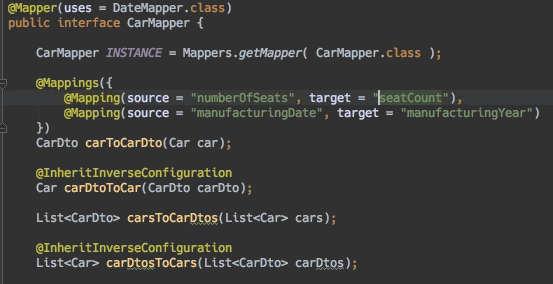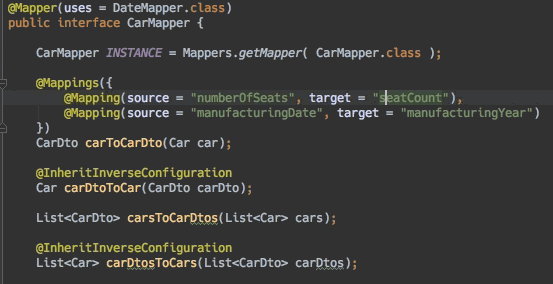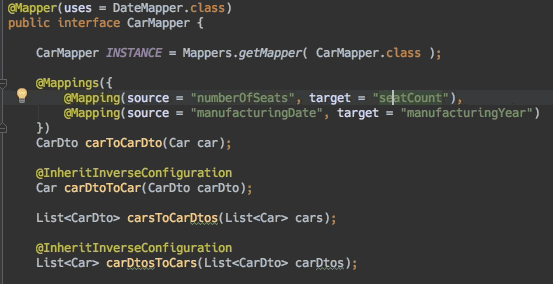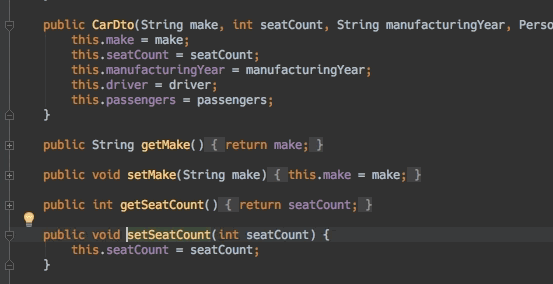
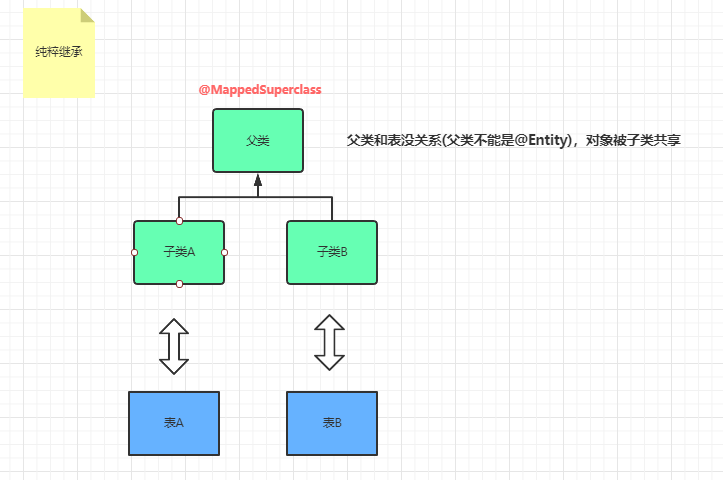
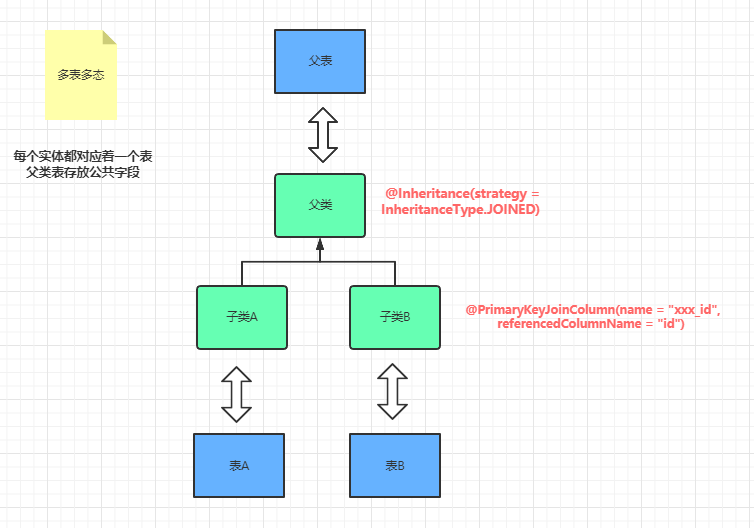
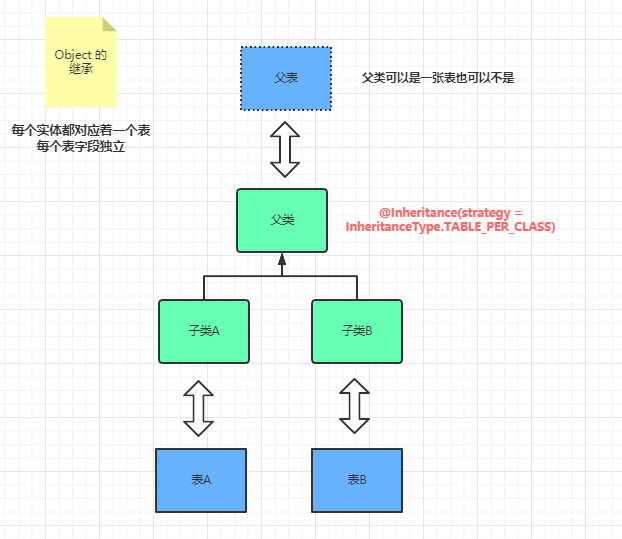
2 应用篇—纸上得来终觉浅
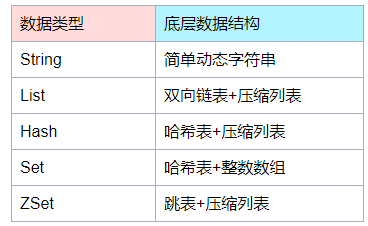
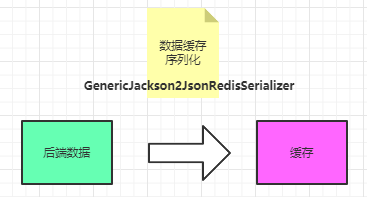
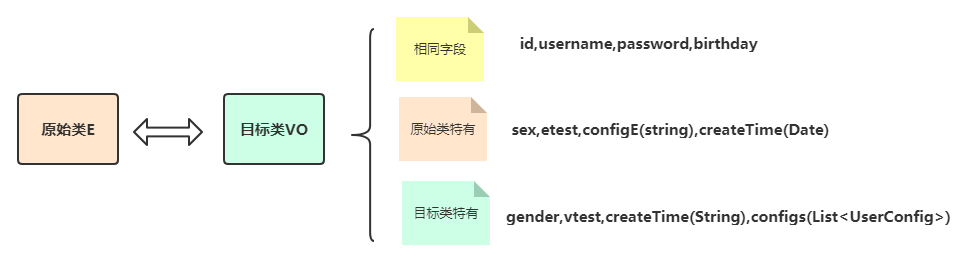
大量键值对保存
场景案例
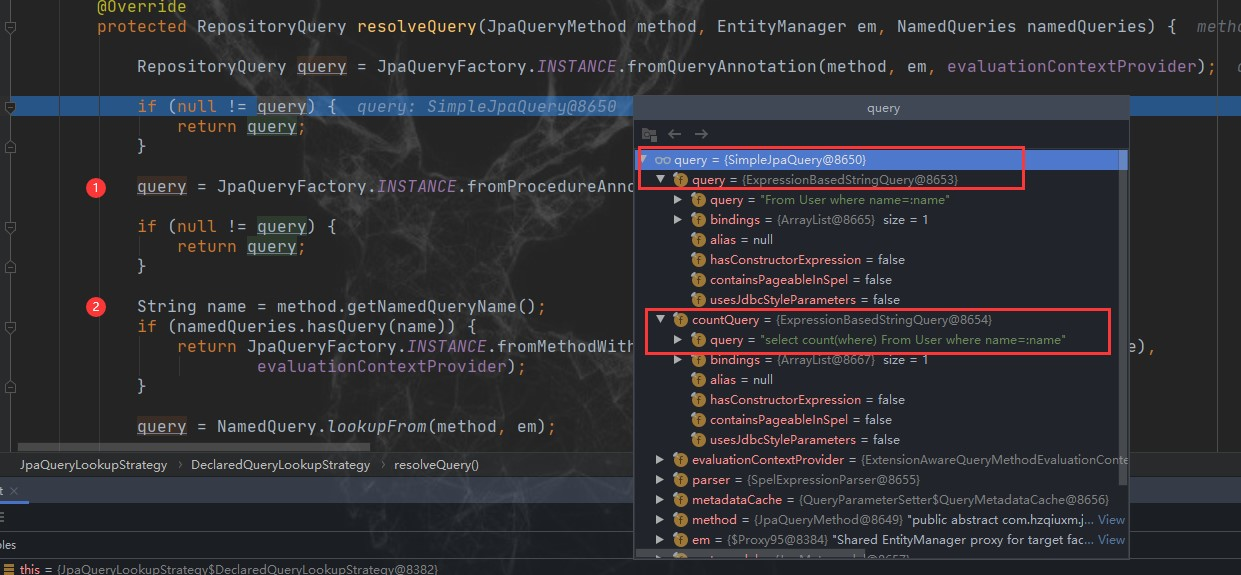
有这么一个需求场景,一个图片存储系统,图片的ID刚好可以对应和存储对象ID,所以采用了String类型来保存,键值的长度都是10位数。
刚开始,保存了大约1亿张图片,发现占用内存约6.4G。此时还算正常,当图片数量继续增加到2亿时开始出现由于要生成RDB而导致响应变慢了。
请问如何优化?
首先我们得找到变慢的原因,直接原因是RDB持久化文件太大所致
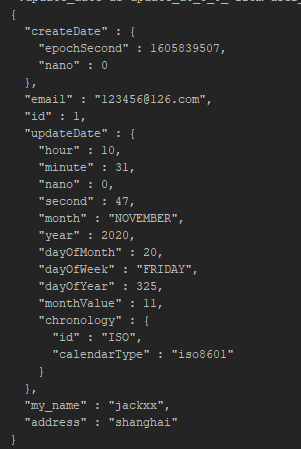
按道理来说,10位数整型无法存储,使用long型8个字节绝对够了,键值加一起也就16个字节;1个字节1B,16个字节16B;
1亿张图片为16亿B,约等于1.6G,为什么实际情况是6.4G?
那我们不禁要问,理论与实际为何相差这么大?
要回答这个问题,就需要对String的类型做个彻底的解剖。
疑团解析
之前介绍过Redis值中的String类型底层存储结构是简单动态字符串(SDS),其实它的存储结构如下:

比如上图中,key1和key2两个元素,它们都通过a、b、c三个无偏哈希函数进行计算落到不同的位置上,记为1。
当向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都位 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致(这就是误判)。
如果这个位数组比较大,错误率就会很低,如果这个位数组比较小,错误率就会比较大。当然位数组太大,所需要的hash函数就越多,会影响计算效率的。
我们发现为了存储已用长度、实际分配长度、结束符号信息需要额外的9个字节!比我们实际数据本身还要大。
这还没完,对于 String 类型来说,除了 SDS 的额外开销,还有一个来自于 RedisObject 结构体的开销。
因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,同时指向实际数据。
一个 RedisObject 包含了 8 字节的元数据和一个 8 字节指针,这个指针再进一步指向具体数据类型的实际数据所在,当SDS是Int或Long类型时,指针就不需要了,指针位置可以直接存放数据,节省空间开销。
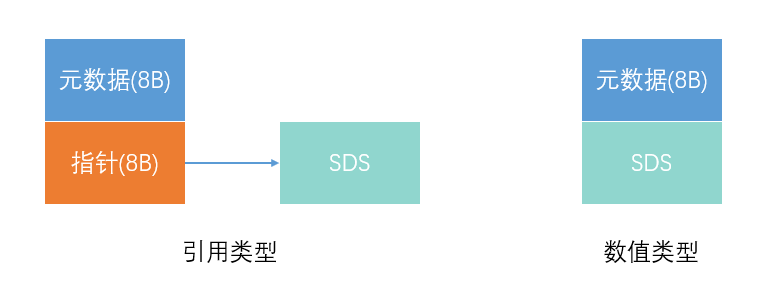
本场景中采用的是后一种:数值类型的。所以又额外多出来8个字节信息要存储。
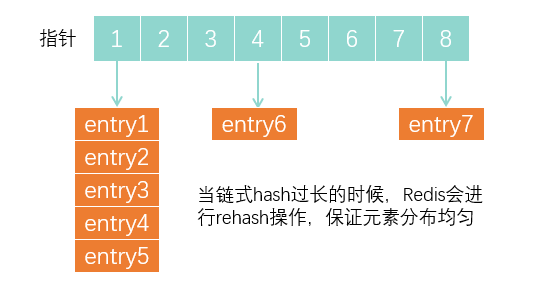
但是好像加起来也不到64个字节呀?没错,这还没有完!因为在全局哈希表中,还要存储指针,entry值,链式指针
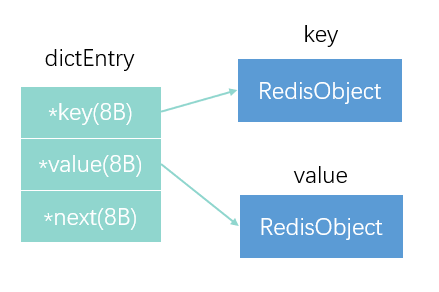
虽然三个指针只占了24个字节,但是Redis通常会多分配一些内存,一般往上按照2的幂次数取到32字节,以此来减少分配次数。
所以虽然数据本身只占了16个字节,但是还需要额外的48个字节存储其它信息。
这就是1亿个10位键值对真实存储情况。
优化手段
明白了简单动态字符串存储原理后,也理解了为什么1.6G的数据为什么占用了6.4G内存。那能换成哪种结构来节约内存呢?
回顾下存储方式的底层数据结构,我们可以发现有个叫压缩列表的数据结构,它是一种非常节省内存的结构。
表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量,以及列表中的 entry 个数。压缩列表尾还有一个 zlend,表示列表结束。
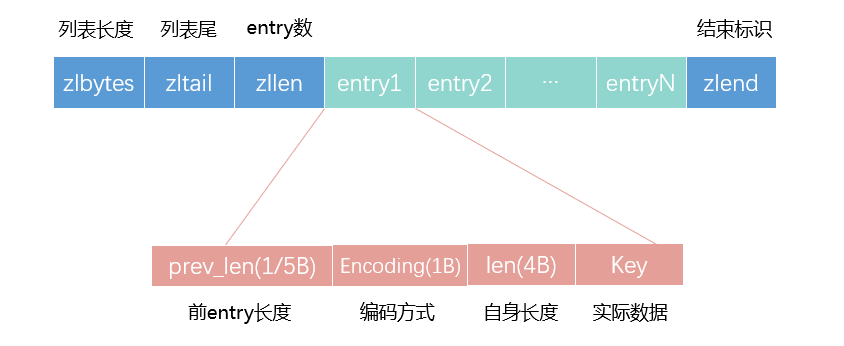
- prev_len,表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节。虽然 1 字节的值能表示的数值范围是 0 到 255,但是压缩列表中 zlend 的取值默认是 255,因此,就默认用 255 表示整个压缩列表的结束,其他表示长度的地方就不能再用 255 这个值了。所以,当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。
这些 entry 会挨个儿放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。
在上述场景中每个对象大小都是固定的8字节,所以prev_len占1个字节,加上编码方式1字节,自身长度4字节,实际数据8字节,一个entry大约14字节就够了
String的额外开销最大的部分为dictEntry部分,大约占了32个字节,因为每一个键值对entry都对应一个dictEntry。而压缩列表将entey都按顺序放在一起,若干个entry只需要对应一个dictEntry,可以节省下许多额外的空间。
不过redis官方一直在优化各种数据结构的保存机制,不同的版本得到的值可能不太一样,大家千万不要拘泥与值的大小,而是通过存储机制的不同,选择适合的数据结构。这里有一个小工具,可以在线计算各种键值对长度和使用数据类型的内存消耗大小,在实际应用中一定要先测试下所用版本的真实情况,版本不同差别很大。
推荐的神奇小工具:Redis容量预估-极数云舟
海量keys统计
场景1 聚合计算
需要系统中保存所有登录过的用户ID和每一天登录过的用户ID;所有登录过的用户ID可以使用Set来保存,key为user:id,value就是具体的userId值
每天的登录用户也可以使用SET来保存,不过需要有时间戳,可以把时间戳设计在key中,比如key设计为:user:id:20210202就表示2021年2月2号登录的用户ID集合
每天的新增用户,其实就是在当前的用户集合中把存在在累计用户集合中的用户剔除掉,所以只要用日用户Set与累计用户set做差集即可
第二天的留存用户,相当于在前一天的新增用户数还存在于当天的日用户Set中,很明显就是求二者的交集
场景2 排序计算
出现最XXX的字眼时,我们很容易联想到包含了排序,所以使用ZSet方式存储,我们自己来决定每个元素的权重值,比如时间戳先后。
实现起来就很简单了,因为ZSet就是按照权重自动排序的,我们要做的就是使用命令直接来获取即可
比如:ZRANGEBYSCORE comments N-99 N 假设最新评论权重是N,那么这个语句就代表获取最新的100条评论
场景3 二值状态统计
打卡的状态很有限,只有两种情况,要不打了,要不没打,所以我们称之为二值状态的统计问题。
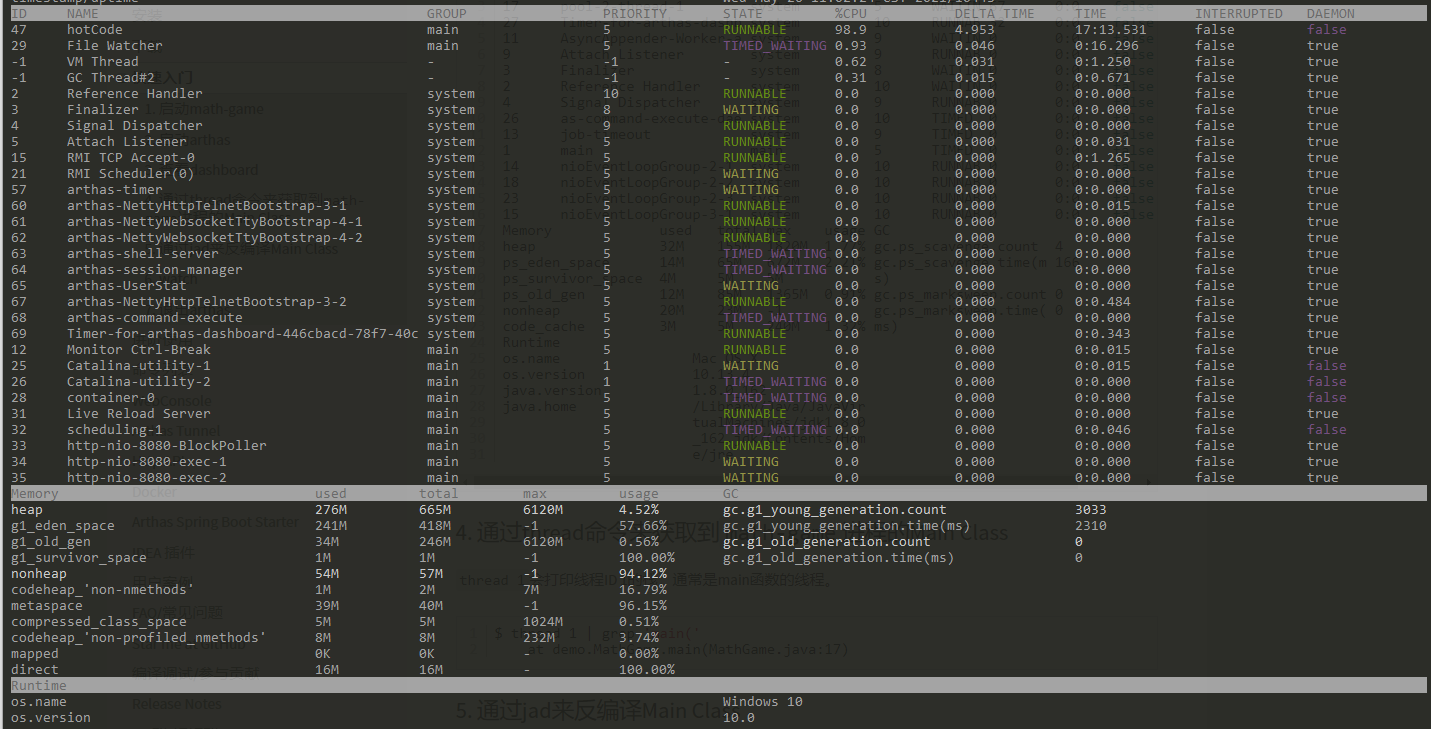
在签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
我们就可以选择Redis 提供的扩展数据类型 Bitmap ,它的底层数据结构实现其实也用String类型,我们可以把它看出是一个bit数组。
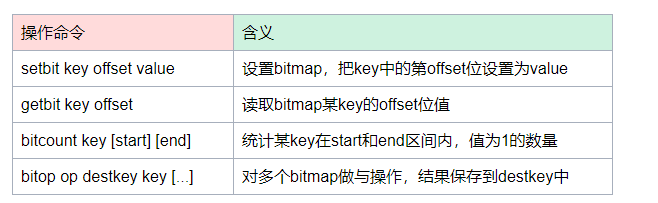
多少个1,就表示有多少个用户连续10天打卡签到。
有人看到有1亿位的bitmap是不是被吓了一跳,是不是担心内存开销过大,能存的下吗?我们尝试来计算下,1亿除以8转换为字节,然后除以1024转换为KB,再除以1024转换为MB,大约等于12,那么10天的数据也就占了120M的内存,如果再结合TTL的使用,及时释放掉不需要的签到记录,内存压力不算太大。
只要是能够转换为二值状态统计的问题,我们都可以使用bitmap去做,这样可以有效节省内存空间。
场景4 基数统计
统计网页的UV我们需要进行去重操作,那么第一反应就是使用Set了,然后使用SCARD命令很方便就得到UV数了。
但是由于网页的访问量实在是打,是千万级别,那么一个Set就要记录千万个用户ID了,这样的页面有1000个,那内存消耗就有点大了。
我们再进一步思考,我们统计UV是否需要特别精准呢?一般是不需要特别精准的,只要差值别超过一个数量级,就有它的统计学意义了。
此时,我们可以使用Redis 提供的 HyperLogLog 了,是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。你看,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。
虽然误差率不算大,但是,如果你的业务场景需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型,计算好你需要的内存。
统计计算宝典
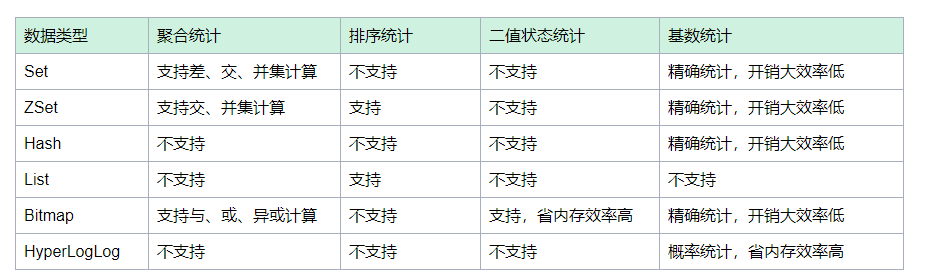
该表只是提供一些常规场景的思路和建议,并不能涵盖Redis各种统计场景,大家可以不断更新此表。
大数据过滤
需求场景
某平台需要给用户不断推荐新的新闻内容,它每次推荐时要进行去重,去掉那些已经看过的内容,请问怎么去做?
大部分人的第一反应是通过Set来存储新闻的唯一编号,利用set天然去重。
当然我们的解决方案不可能这么简单,试想下如此多的历史记录全部缓存起来,那得浪费掉多大存储空间呀?且访问是按照线性增长的,时间越久性能就越差,宝贵内存资源浪费也越严重。此时我们就可以使用Redis中的布隆过滤器来解决。
布隆过滤器就是专门用来解决这种去重问题的,可以节约大量的空间,但存在一定的误判。
我们可以把布隆过滤器看成一个不那么精确的set,当它说某个值存在时,可能是不存在的;但是当它说不存在,那肯定是不存在的。用在上面场景里就是:当它说新闻是新的时候,那一定是新的;当它说新闻不是新的时候,有可能是新的,这个结果满足了上述场景要求。
插件安装使用
布隆过滤器是以插件的形式发挥作用的,可以前往Releases · RedisBloom/RedisBloom · GitHub进行下载源码编译安装,遵从以下步骤
- 解压缩后使用
make编译生成动态链接库redisbloom.so
- 拷贝动态链接库:
cp redisbloom.so usr/local/bin/
- redis.conf配置文件中添加动态链接库:
loadmodule redisbloom.so
- 重启redis
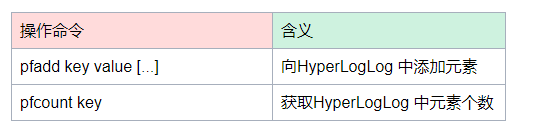
布隆过滤器主要操作:
模拟新闻编号判断:
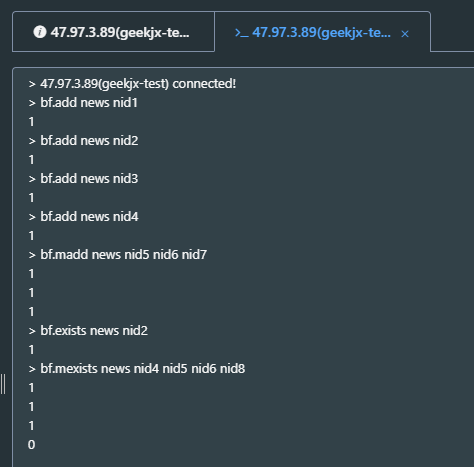
好像很准确啊,一个也没有误判,那是因为我们数据量太小。根据笔者实验,一般几百数据量的情况下就会出现误判。
另外其实我们是可以通过bf.reserve参数来重新设置过滤器的误判率的:

在我们实际的互联网环境下,有很多技术都利用了布隆过滤器的原理,比如爬虫系统判断URL是否爬过。
还有NOSQL领域的: HBase、Cassandra 还有 LevelDB、RocksDB 内部都有布隆过滤器结构,布隆过滤器可以显著降低数据库的 IO 请求数量。当用户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后再去磁盘进行查询。
邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平 时也会遇到某些正常的邮件被放进了垃圾邮件目录中,这个就是误判所致,概率很低。
分布式锁设计
基于Redis的分布式锁设计一般分为单机的redis和集群的redis
单个Redis分布式锁
业界通用的设计方案就是利用SETNX 和 DEL 命令组合来实现加锁和释放锁操作。伪代码如下:
// 加锁
SETNX lock_key 1
// 业务逻辑
DO THINGS
// 释放锁
DEL lock_key
//超时释放
Expire lock_key
上述伪代码还存在两个潜在风险:1 业务逻辑发生异常或宕机,导致释放机制失效;2 业务逻辑执行时间过长,锁超时或被其它线程释放了,导致并发问题
第一个风险我们可以加上一个异常捕获,先解决异常情况下的锁释放问题,然后利用redis提供的新方法:
SET key value [EX seconds | PX milliseconds] [NX]
命令示例:Set lock:bizxxx true ex 5 nx
让redis保证SETNX和Expire指令的原子性;
第二个风险我们可以引入随机数(客户端唯一标识也行),验证随机数保证了锁不会被其它线程释放掉,由于随机数的判断和删除缺乏原子性,我们还需要引入LUA脚本,保证随机数品判断匹配和删除的逻辑的原子性。
整个过程伪代码:
//unlock.script是Lua脚本
redis-cli --eval unlock.script lock_key , unique_value
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
Redis集群分布式锁
当我们要实现高可靠的分布式锁时,就不能只依赖单个的命令操作了,我们需要按照一定的步骤和规则(分布式锁算法)进行加解锁操作,否则,就可能会出现锁无法工作的情况。
Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。
这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失。
整个分布式加锁可以分为3个步骤:
- 1 客户端获取当前时间
- 2 客户端按顺序依次向 N 个 Redis 实例执行加锁操作
- 3 一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时
加锁成功要满足两个条件:1 客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;2 客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
当然不推荐大家去根据算法去实现分布式锁,可以的话还是采用开源或已成熟的解决方案
分布式锁小结
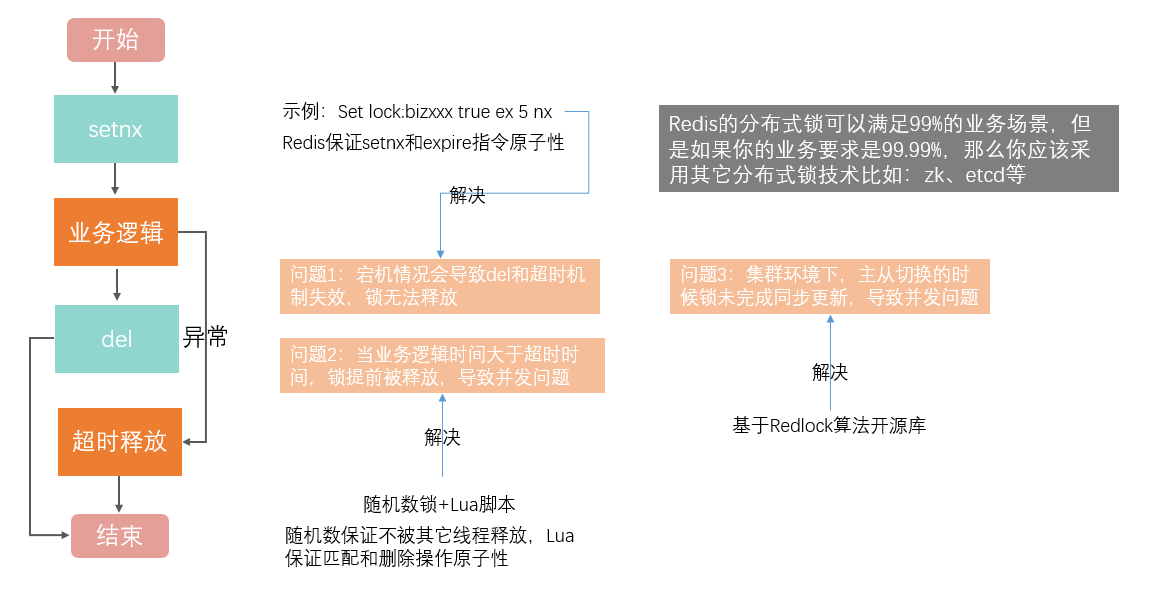
我个人认为Redis的分布式锁是一个比较轻量的解决方案,可以满足我们99%的业务场景,但是如果你的业务要求是99.99%,甚至更高,那么你应该采用其它分布式锁技术比如:zk、etcd等,确保万无一失。
附录一:位数与存储大小计算

要计算多少位数需要多少个字节来保存,我们首先要清楚2的多少次方的计算结果能覆盖我们要保存的数据位数。
比如我们要保存一个10位数,10位数在数值大小上是十亿,我们要保证覆盖最大十亿数,那么到达百亿就能满足了。
根据2的指数运算:
2的34次方的时候达到了百亿,也就是2的34次方对应需要多少个字节呢?我们都知道1个字节占8位,34位大约是4.25个字节。
但是我们要知道在计算机语言中,数据是有类型的,int型最大的能表示的数为2的32次方,也就是十亿级别的,既然int型数据不能满足要求,那就只能采用long类型了
long的类型能表示的数为2的64次方,这个数太大了,足足有20位,满足10位数绰绰有余,而64位,占了8个字节。
附录二:HyperLogLog 原理
HyperLogLog使用非常简单,其实现依据说起来也很简单,但是证明理解起来就没那么简单了,需要用到概率学的知识
先讲下依据,HyperLogLog 是利用概率结果来估算实验次数,是不是看起来有点神奇和懵逼?
举个具体的例子:某天吃完饭,你和你女朋友玩抛硬币游戏,你女朋友负责抛硬币,她抛了的轮数记为n,每一次都会记录正面是在本轮中第K次出现的。然后她告诉你K的最大值,让你猜n的值。
作为理工男的你马上意识到这是个伯努利过程在脑海里进行了概率计算:
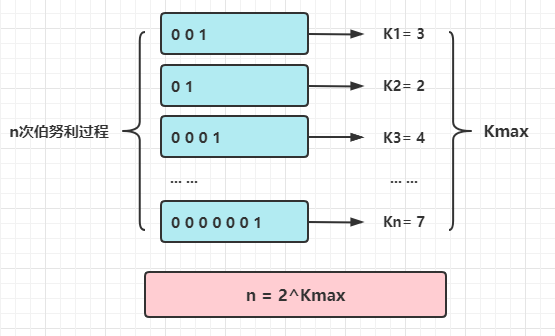
算了下kmax在回合出现的概率是(1/2)^k * max,得到: n = 2^k * max,当你女朋友告诉你最大K=3,你胸有成竹的脱口而出:8!
结局是她只抛了1次,于是你输了,负责刷碗。
并不是你的计算不对,而是单次的概率不符合大数定律,而Philippe Flajolet教授吸取了你的教训,引入了桶的概念,再利用调和平均数减少误差。

其中m是桶的数量,const是修正常数,它的取值会根据m而变化。
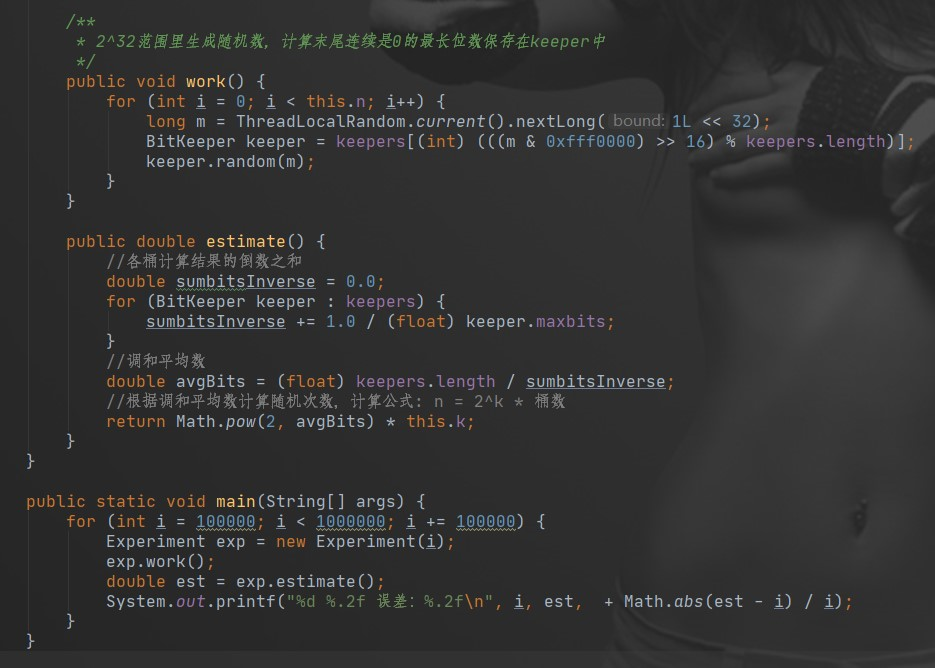
笔者写了一个简化版测试程序,计算了下误差值,真实算法更复杂,误差值也更低
100000 96673.07 误差:0.03
200000 196276.45 误差:0.02
300000 295135.37 误差:0.02
400000 396655.24 误差:0.01
500000 506963.14 误差:0.01
600000 603743.24 误差:0.01
700000 759724.06 误差:0.09
800000 803806.54 误差:0.00
900000 892418.41 误差:0.01
上面代码用了1024个桶,而在 Redis 的 HyperLogLog 实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最大可以表示 maxbits=63,于是总共占用内存就是 2^14 * 6 / 8 = 12k字节。
帮助我们理解原理的工具:Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure – AK Tech Blog (neustar.biz)
附录三:布隆过滤器原理
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的hash值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个hash函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。

 菡萏如佳人
菡萏如佳人