小谈SpringApplication启动
基于Springboot2.0+版本
前言
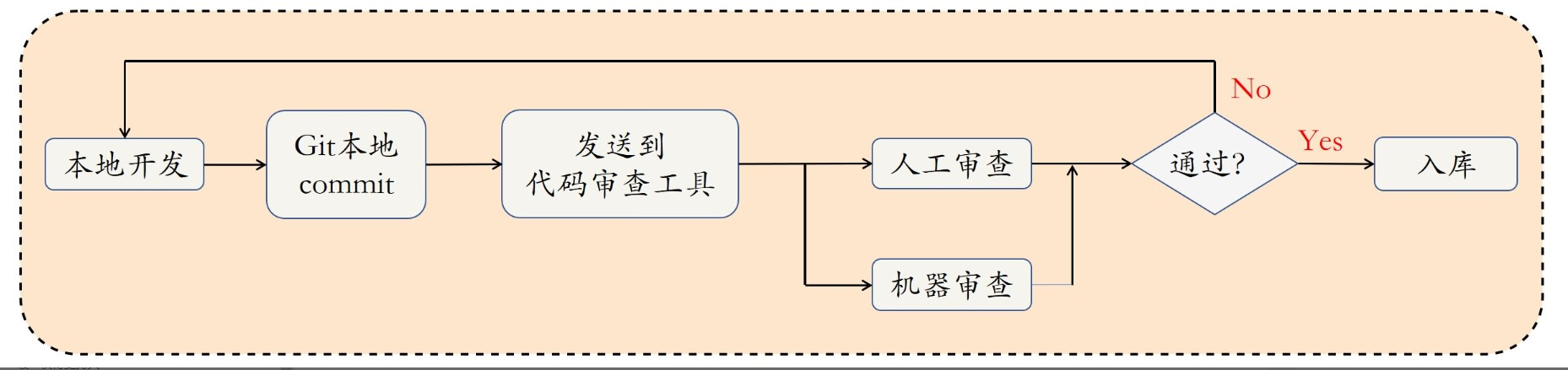
在Springboot装配入门指南中我们简单了解了下组合注解@SpringbootApplication,它的本质是一个配置角色注解模式,同时开启了自动装配等功能。那我们是如何启动一个Springboot项目的呢?
使用Spring官方提供的网页: https://start.spring.io/ 中生成的项目,都会自动生成一个启动类,该启动类都会使用@SpringbootApplication进行标注,main方法中会统一使用SpringApplication.run()方法来启动。
我们今天的主角就是SpringApplication,谈谈它的启动和运行过程,其中会涉及到上下文应用加载、应用事件加载、应用监听器,应用推断、引导类推断、应用广播等概念
SpringApplication启动
自定义启动
调用run方法启动,例如:SpringApplication.run(MocApplication.class, args);这个大家都很熟悉了,那如果我们自定义启动怎么去实现呢?
大概的步骤是定义一个SpringApplication实例,然后运行时传入run方法需要的两个参数即可。
我们自定义时有两种API方式进行选择:一种是通过SpringApplicationAPI 调整,一种是通过SpringApplicationBuilderAPI调整。二者实现方式分别如下:
第一种:SpringApplicationAPI 方式
public class MySpringApplication {
public static void main(String[] args) {
Set<String> sources = new HashSet();
sources.add(ApplicationConfiguration.class.getName());
SpringApplication springApplication = new SpringApplication();
springApplication.setSources(sources);
springApplication.setBannerMode(Banner.Mode.CONSOLE);//banner打印模式设置
springApplication.setWebApplicationType(WebApplicationType.NONE);//web应用类型设置
springApplication.setAdditionalProfiles("dev");//环境设置
springApplication.setHeadless(true);//图形界面设置
springApplication.run(args); //启动
}
@SpringBootApplication
public static class ApplicationConfiguration {
//故意不使用MySpringApplication类作为run的参数
}
}
第二种:SpringApplicationBuilderAPI 方式,使用了生成器模式书写起来比较流畅
public class MySpringApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(MySpringApplication.class)
.bannerMode(Banner.Mode.CONSOLE)
.web(WebApplicationType.NONE)
.profiles("dev")
.headless(true)
.run(args);
}
}
启动run方法源码简单说明
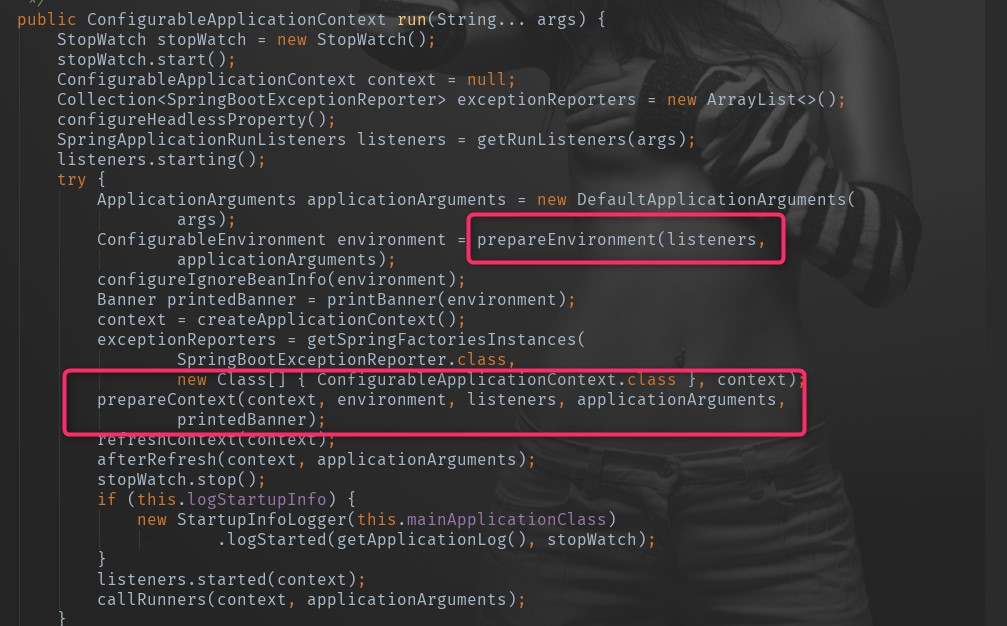
两种方式其实没有什么大的差别,只是书写的时候第二种采用了builder设计模式。我们跟踪原来可以发现,最后run方法返回的是一个ConfigurableApplicationContext,run方法的主要源码如下:
StopWatch stopWatch = new StopWatch(); //构造一个观察器,用来记录时间
stopWatch.start();//启动观察器
ConfigurableApplicationContext context = null; //最终返回的应用上下文
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>(); //启动异常报告
configureHeadlessProperty();//设置java.awt.headless系统属性为true (代表没有图形化界面)
SpringApplicationRunListeners listeners = getRunListeners(args);// 获取应用监听器(注解一)
listeners.starting(); //启动监听器
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments( //构造一个应用程序参数持有类
args);
ConfigurableEnvironment environment = prepareEnvironment(listeners,applicationArguments);// 准备Environment(注解二)
configureIgnoreBeanInfo(environment);//过滤指定配置的Bean
Banner printedBanner = printBanner(environment);//按指定的方式打印banner
context = createApplicationContext(); //创建一个Spring应用上下文,即我们平时说的Spring容器(注解三)
exceptionReporters = getSpringFactoriesInstances(
SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);//准备异常报告
prepareContext(context, environment, listeners, applicationArguments,printedBanner);//上下文前置处理
refreshContext(context); //上下文刷新
afterRefresh(context, applicationArguments);//上下文后置处理
stopWatch.stop(); //停止观察器的计时
... ...
listeners.started(context); //监听已经初始化完成启动的上下文
... ...
listeners.running(context); //监听正在运行中的上下文
... ...
return context; //返回Spring上下文容器
关于上面源码的额外注解会下面章节进行额外的说明,这里只是对启动过程有个大概了解,然后对主要的注解步骤有个印象。
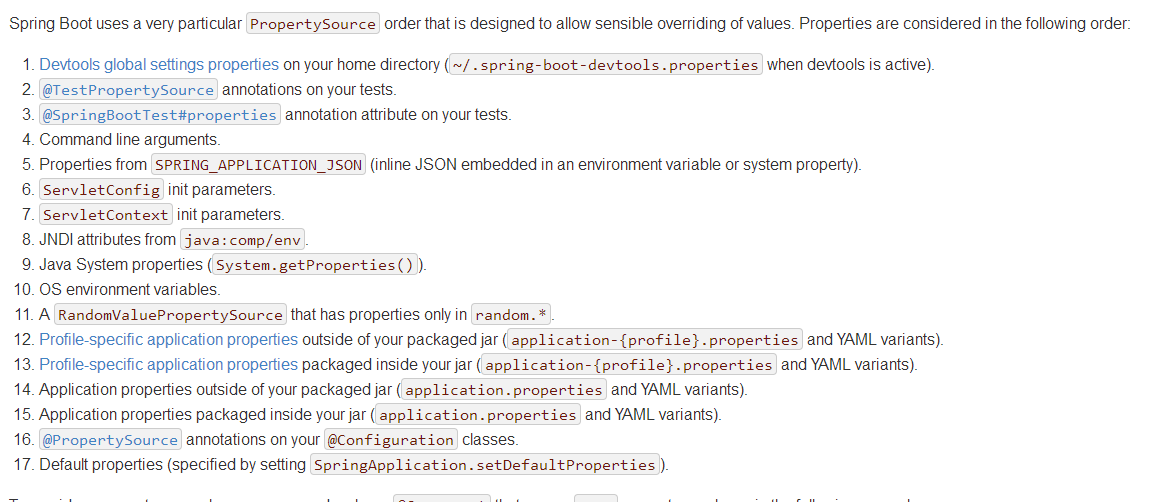
配置Springboot Bean源
Java 配置 Class 或 XML 上下文配置文件集合,用于 Spring Boot BeanDefinitionLoader读取,并且将配置源解析加载为Spring Bean 定义,数量:一个或多个以上。
一般有两种来实现:一种是采用java配置class方式,就是使用 Spring 模式注解所标注的类,如@Configuration;另一种是传统XML方式,一般我们在新项目中使用第一种方式,无法支持或兼容老的XML配置可以使用@Import来导入XML配置文件。
推断Web应用类型
什么是推断Web应用类型?我们知道在Springboot2.0中(其实是Spring5.0中)加入了Reactive的异步编程模式,用来替代原来传统的servlet方式。所以我们的应用可以是新型的REACTIVE类型,可以是传统的SERVLET类型,还可以是不属于前二者的非WEB类型。
我们可以像之前例子中手动指定某个类型比如:WebApplicationType.NONE,你不指定的话,SpringApplication是会自动推断的。
怎么自动推断呢?在SpringApplication的构造函数中,我们可以看到一个方法 WebApplicationType.deduceFromClasspath(),这个方式就根据classpath中是否包含特定的类来推断属于哪一种,都没有特定类的时候为非WEB应用,SERVLET和REACTIVE以SERVLET为优先,具体逻辑大家可以查看源码。
三者对应关系类型如下:
Web Reactive:WebApplicationType.REACTIVE
Web Servlet:WebApplicationType.SERVLET
非 Web:WebApplicationType.NONE
推断引导类
除了对应用类型进行推断外,SpringApplication还会进行引导类(Main Class)推断。源码如下:
private Class deduceMainApplicationClass() {
try {
StackTraceElement[] stackTrace = new RuntimeException().getStackTrace();
for (StackTraceElement stackTraceElement : stackTrace) {
if ("main".equals(stackTraceElement.getMethodName())) {
return Class.forName(stackTraceElement.getClassName());
}
}
}
catch (ClassNotFoundException ex) {
}
return null;
}
```
从上面源码可以看出,它是根据 Main 线程执行堆栈信息来判断实际的引导类的,就像我们在自定义SpringApplicationAPI 方式时,故意将配置注解标注在新建了的一个类上。最后也是可以启动成功的。
#### 加载应用上下文初始器
在SpringApplication构造器中,除了上面介绍的二个推断外,另外一个重要的操作就是加载应用上下文初始器:ApplicationContextInitializer。其原理是利用 Spring 工厂加载机制,实例化ApplicationContextInitializer实现类,并排序对象集合。相关源码如下:
```
private Collection getSpringFactoriesInstances(Class type,
Class[] parameterTypes, Object... args) {
ClassLoader classLoader = getClassLoader();
Set<String> names = new LinkedHashSet<>(
SpringFactoriesLoader.loadFactoryNames(type, classLoader));
List<T> instances = createSpringFactoriesInstances(type, parameterTypes,
classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
实现类:SpringFactoriesLoader,在固定路径下配置相关资源:META-INF/spring.factories,顺序的设置依赖 AnnotationAwareOrderComparator#sort
加载应用事件监听器
我们自定义事件监听器的话也是利用 Spring 工厂加载机制,实例化ApplicationListener实现类,并采用排序对象AnnotationAwareOrderComparator来设置加载的顺序。下面是二个自定义ApplicationListener实现例子,顺序设置上分别采用@Order注解方式和实现Ordered接口方式。
第一种,@Order注解方式:
@Order(Ordered.HIGHEST_PRECEDENCE) //优先级最高,对应最小整数
public class OneApplicationListener implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
System.out.println("One: " + event.getApplicationContext().getId()
+ " , timestamp : " + event.getTimestamp());
}
}
第二种,Ordered接口方式
public class TwoApplicationListener implements ApplicationListener<ContextRefreshedEvent>,Ordered {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
System.out.println("Two: " + event.getApplicationContext().getId()
+ " , timestamp : " + event.getTimestamp());
}
@Override
public int getOrder() {
return Ordered.LOWEST_PRECEDENCE; //最低优先级,对应最大整数
}
}
对应的配置文件spring.factories内容:
org.springframework.context.ApplicationListener=\
com.imooc.diveinspringboot.listener.TwoApplicationListener,\
com.imooc.diveinspringboot.listener.OneApplicationListener
启动我们之前自定义的SpringApplication应用后,我们可以看到控制台日志中会输出两个应用事件监听器加载信息,虽然One配置在Two后面,但是最后打印的顺序是根据Ordered设置的值来决定的。
SpringApplication运行
至此介绍完了SpringApplication准备阶段的一些主要事情,接下来主要介绍运行阶段(run方法中)的一些主要事情
加载运行监听器(注解一)
类似ApplicationListener的实现,也利用 Spring 工厂加载机制,读取SpringApplicationRunListener对象集合,并且封装到组合类SpringApplicationRunListeners。
我们查看springboot的spring.factories可以看到SpringApplicationRunListeners 内部实现是EventPublishingRunListener,它利用 Spring Framework 事件API ,广播 Spring Boot 事件。
如果我们要自定义实现的话可以仿照EventPublishingRunListener去实现。
SpringApplicationRunListeners监听多个运行状态方法,具体如下:
监听事件
完成一个自定义监听事件的步骤分为三步: 1. 定义事件 2.注册到监听器 3.发布事件
Spring 应用事件可以分为两类:普通应用事件(ApplicationEvent)和应用上下文事件(ApplicationContextEvent),后者继承了前者。一般我们实现的时候继承前者即可。下面是一个自定义事件的例子:
public class MyEvent extends ApplicationEvent {
public MyEvent(Object source) {
super(source);
}
}
注册到监听器有两种方式:接口编程(实现ApplicationListener,它是一个函数式接口)和注解编程(@EventListener),二者例子如下:
第一种,接口编程方式;
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
// 注册应用事件监听器
context.addApplicationListener(event -> {
System.out.println("监听到事件: " + event);
});
第二种,注解编程方式;
@Component
public class MyEventListener {
@EventListener //注册应用事件监听器
@Async //异步执行
public void onListener(MyEvent event){
System.out.println("The event is : " + event);
}
}
}
最后一步是发布事件,事件的刷新和关闭也属于一种事件,在上面第一种实现方式中增加下面的代码会触发5个事件:
//会监听到5个事件
context.refresh(); // 刷新上下文
// 发送事件
context.publishEvent("hello");
context.publishEvent("world");
context.publishEvent(new ApplicationEvent("hzqiuxm") {
});
context.close(); // 关闭上下文
EventPublishingRunListener监听方法与 Spring Boot 事件对应关系:
最后提下EventPublishingRunListener实现类中进行Spring 应用事件广播是通过SimpleApplicationEventMulticaster类来实现的,它的执行方式有同步和异步两种。
SimpleApplicationEventMulticaster实现的是Spring 广播器接口:ApplicationEventMulticaster。
创建应用上下文(注解三)
在注解三的代码处生成我们最终得到的应用上下文(ConfigurableApplicationContext)容器。
根据准备阶段的推断 Web 应用类型去创建对应的ConfigurableApplicationContext实例,不同类型对应的应用上下文也不同,具体关系如下:
Web Reactive:AnnotationConfigReactiveWebServerApplicationContext
Web Servlet:AnnotationConfigServletWebServerApplicationContext
非 Web:AnnotationConfigApplicationContext
具体细节这里就不叙述了。
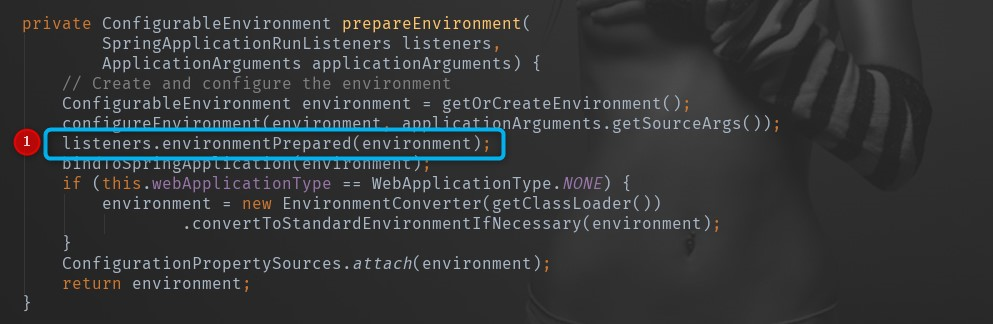
创建Environment(注解二)
这里主要是根据准备阶段的推断 Web 应用类型创建对应的ConfigurableEnvironment实例,也有三种类型:
Web Reactive:StandardEnvironmentWeb
Servlet:StandardServletEnvironment
非 Web:StandardEnvironment
总结
经过介绍,我们大致清楚SpringApplication的启动主要分为两个阶段:启动阶段(准备阶段由构造方法完成)与运行阶段(调用run方法完成)。
启动阶段其中主要涉及到了web类型推断、引导类推断、初始化器以及监听器加载这几个概念,我们如果要实现自定义的监听器,它们都需要利用Spring工厂加载机制,再通过META-INF/spring.factories完成定义。
运行阶段其中主要有一个SpringApplicationRunListeners的概念,它作为Spring Boot容器初始化时各阶段事件的中转器,将事件派发给感兴趣的Listeners(启动阶段得到的)。这些阶段性事件将容器的初始化过程给构造起来,提供了比较强大的可扩展性。
如果作为应用开发者要对Spring Boot容器的启动阶段进行扩展会有哪些方式呢?我想至少有下面几种:
 菡萏如佳人
菡萏如佳人