菡萏如佳人
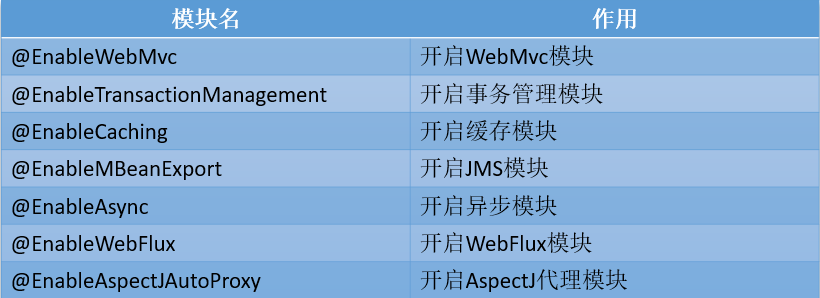
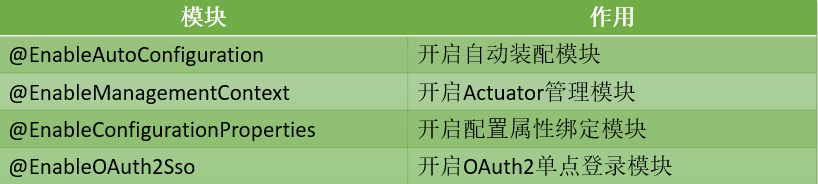
菡萏如佳人OOD设计原则
面向对象的分析设计有很多的原则,这些原则从思想层面给我们以指导,是我们进行面向对象设计应该尽力遵守的体现。
学习设计模式之前,应该要对设计原则做个简单的了解,只有这样我们在学习设计模式的时候,才能把某个场景的具体解决方案与设计原则联系起来。
某个设计模式可能遵守了几个设计原则,也可能违背了某个设计原则。我们不要把设计模式看成是银弹,同样设计原则也不是。
下面介绍几个主流的OOD设计思想,希望对你学习设计模式或进行业务设计时有所帮助。
单一职责原则 SEP

核心思想
所谓单一职责其核心思想指的是:一个类应该只有一个引起它变化的原因
实际应用举例
上面这句话中“变化”就是代表职责,如果一个类有多个引起它变化的原因,那么就意味着这个类的职责太多了,职责耦合性太强,需要拆分。
换句话所有人口都会念但大多数都不知道怎么做的就是:高内聚低耦合。
这个职责理解起来好像很简单,但是在实际的业务场景中是很难完全做到的。难点就在于如何区分“职责”。这是一个没有标准量化的东西,哪些算职责?哪些职责属于一类?职责应该多大的粒度?怎么细化?所以这个原则也是最容易被违背的。
我们举一个用户服务例子来分析下:
public interface IuserService{
void setHeight(double height);
double getHeight();
void setWeight(double weight);
double getWeight();
double updateHeight();
boolean addRole();
}
这个例子还是十分简单的,很明显身高height和体重weight是属于用户的对象属性,更新身高addRoleupdateHeight和增加角色是属于用户的行为属性,它们属于不同的职责,在实际实际中对象属性一般放在实体或值对象中,而后者一般是放在具体业务实现中。太简单了?你已经完全掌握了?我们再看一个例子:
public interface Iphone {
//拨号
public void dial(String phoneNumber);
//通话
public void chat(Object obj);
//挂断
public void hangup();
}
这个Iphone有没有问题?一般人还真看不出来,很多源码和设计都是这样设计的。那么它满足我们单一职责的原则吗?其实是不满足的,拨号和挂断负责的是通讯协议管理(连接和断开),而通话负责的是数据传输(把通话内容进行传输与信号转换)。看来职责是不同的,那么职责之间会互相影响吗?
拨号连接的时候,只要能接通就行了,至于是电信的还是移动协议不用关心;电话连接好后,关心传递什么数据吗?不关心!所以我们的最佳选择是什么?拆!把负责通讯的放在一个接口,把负责数据传输的放在一个接口,然后用一个公共的实现类去实现这两个接口(不要单独实现接口然后使用组合模式,太复杂了)。
OK到目前为止,完美满足SRP了!但是有时候我们的业务真的都要做到这么完美?不一定。请结合项目的可变因素、不可变因素、项目工期、人员组成、成本收益等找到适合你的平衡点。
实践原则建议
几乎不可能做到一个类真的只有一个职责,但是我们可以区分一个类如果有多个职责的话,那么这些职责中哪些是变化的?
我们可以把业务上不变的职责放在一起,做到多个职责中只有一个职责才会变化(频繁),那原则上,这个设计也是满足单一职责原则的。进一步如果一个类有多个变化的职责,但是职责变化是会互相影响或者职责变化不会互相影响但二者变化频率差一个数量级,那也算是一种折中的满足单一职责原则。
接口层面,一定要做到满足单一原则;类的设计嘛,量力而行。
单一职责是接口或类的设计原则,单同时也试用于方法,一个方法尽可能只做一件事。
带来的好处:
- 类的复杂度降低,实现上面职责都有清晰的定义
- 可读性高,提升代码可维护性
- 降低业务变更风险,职责分开修改范围和影响范围都降低了
可能存在的坏处:过于单一职责会导致接口或类关系异常复杂
使用难点:如何划分职责的粗细度,如何成本收益的平衡
里氏替换原则 LSP

核心思想
所谓里氏替换原则其核心思想指的是:子类型必须能够替换掉它的父类型。
实际应用举例
很明显,这是一种多态的使用情况,它可以避免在多态的使用中,出现某些隐蔽的错误。它其实包含了四层意思:
- 1.子类必须完全实现父类的方法
- 2.子类可以增加自己特有的方法
- 3.覆盖或实现父类的方法时输入参数可以被放大
- 4.覆盖或实现父类的方法时输出参数可以被缩小
我们看个例子,就拿之前的手机举例:
手机抽象类实现了一个默认的打电话的方法,并定义了一个操作接口,各种型号的手机继承它就可以了,他们直接就具备可以打电话功能;因为有操作接口,各个手机根据自己是触屏手机还是物理按键手机来进行实现,触屏还分为多种:电容式、电阻式、红外线式、表面声波式。
如果子类不实现父类的方法就无法进行对手机操作,那这样的手机还有是什么用?此外子类可以增加自己其它功能:指纹识别,虹膜识别,人脸识别等。
public abstract class Iphone{
public void dial(String phoneNumber){
checkPhoneNumber(phoneNumber);
doDial(phoneNumber);
... ...
}
假设我们来了手机模型类,这个类怎么处理?直接继承手机抽象类吗?显然是不可以的,手机模型能打电话?不能!那怎么办?
有两种解决办法:
第一种继承后,使用手机类的时候判断下是不是模型,是模型就不能用来打电话。这种方式听上去就不靠谱,每个用到手机类的地方都要加这个判断。
第二种方法,手机模型单独拿出来,它本来就不应该属于手机的一种!那如果是类似苹果推出的itouch(和智能手机功能类似,单不具备打电话,GPS等功能)产品呢?也不应该继承,而是单独作为一个接口或类,大部分手机能做它也能做的事情,可以采用委托的方式交给手机接口去做。
第3点和第4点比较好理解,假设父类入参是hashMap,子类实现的时候可以指定为map,因为map和hashMap也是符合里氏替换原则的,反过来的话就不行了;同理,父类的返回类型是map的话,子类实现的时候可以具体到hashMap,反之则不行。
原则建议
请严格遵守四条原则。
从另外一个角度来说,里氏替换其实是实现开闭原则的重要手段之一。
扩展的一个实现常用手段就是继承,里氏替换原则保证了子类型能够正确替换父类型,只有能正确替换,才能实现扩展,否则扩展了也会出现错误。
难点
带来好处:
- 提高代码的重用性
- 提高代码的扩展性
可能坏处:
- 继承具有侵入性,子类必定拥有父类的属性与方法
- 降低代码灵活性,子类必须要有父类的属性和方法,父类修改了子类就会受到影响
依赖倒装原则

核心思想
所谓依赖倒装原则其核心思想指的是:依赖抽象而不依赖具体类
原则建议
要做到依赖倒置,应该要做到:
- 高层模块不应该依赖于底层模块,二者都应该依赖于抽象
- 抽象不应该依赖于具体实现,具体实现应该依赖于抽象
该思想应该是几个里面最容易理解的,有点类似于面向接口编程,算是大多数项目里实践的最好的一个思想。
它又叫好莱坞原则:不要找我们,我们会联系你。架构设计中的组件解耦或边界单向跨越也体现了该思想
难点
用的好可以使依赖解耦,易于扩展。用的不好就会存在滥用问题,有的业务可能不会有不同的具体实现类,但是也一般会采用面向接口编程的方式
接口隔离原则 ISP

核心思想
所谓接口隔离原则其核心思想指的是:要多少给多少,不要强迫客户依赖他们不用的方法
实际应用举例
这个原则一般用来处理那种非常庞大的接口,这种接口基本也违反了单一职责原则。
客户可能只会使用该接口的部分方法,存在很多不要的方法,那这些方法其实就是接口污染,强迫客户在一堆方法中招自己需要的方法。应该按照不同的客户使用情况来进行分类,哪怕已经符合单一原则了。
这里举一个CTO来如何评价优秀开发工程师的例子,一开始的设计是这样子的:
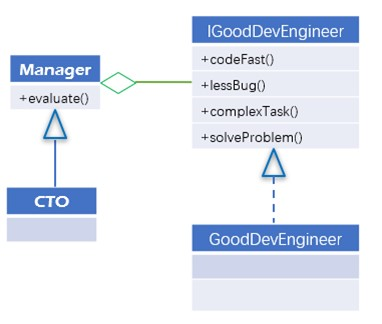
我们定义了一个优秀开发工程师的接口,包含了四个方法,分别代表着优秀开发工程师的四个特点:编码速度快,bug数量少,独立完成复杂任务,技术攻关能力。
看起来一切都很完美,现任CTO通过这四个方法来评价也没啥问题。但是不就之后绩效考核方案调整了,大家都认为全部满足四个特点肯定是优秀的,但是不全部满足的也可以是优秀的。
于似乎优秀工程师分为了两类:编码速度快且bug数量少的和能独立完成复杂人数善于技术攻关的。我们的代码应该怎么修改呢?再写一个扩展类只实现编码速度快且bug数量少的方法?
很明显我们不能这么做,管理层是依赖所有方法的,如果扩展类只实现了部分方法,CTO肯定很懵逼,为什么有的方法没有打印任何信息?
究其原因,其实是优秀工程师的接口过于"庞大"了,其变化的因素包含了两个不同的维度工程师硬技能(编码相关)和软技能(解决问题相关)两部分,好的修改方案应该是把这个接口拆分掉,把硬技能和软技能的分来。
修改后的设计时这样子的:
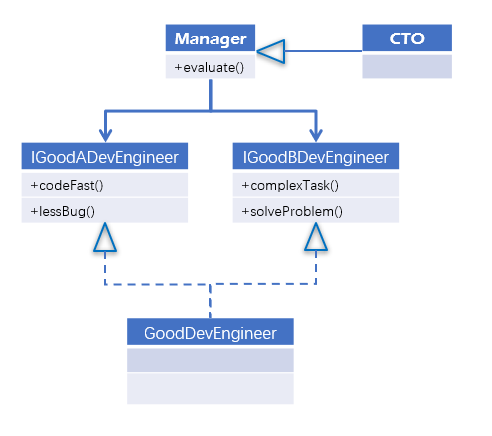
这样重构后,以后你要硬技能优秀工程师还是软技能优秀工程师都可以保持接口不变,增加了灵活性和可维护性。
原则建议
- 一个接口只服务于一个子模块或业务逻辑
- 多注意压缩业务逻辑接口中的public方法
- 已经被污染的接口,尽量去修改,若变更风险大,可以采用适配器模式进行处理
- 合理使用委托、多重继承等方式对庞大的接口进行分离,那多少算庞大?当你的鼠标滚轮滑动3次时,你应该需要仔细考虑该问题了!
- 最后深入了解业务逻辑,最好的接口设计师当然应该是你自己!
难点
接口的设计是有限度的,粒度越小系统越灵活,这是不争的事实。但是,灵活的同时肯定也带来了结构复杂化,开发难度增加。所以这个度的掌握得根据经验和常识判断了。
最少知识原则 LSP

核心思想
所谓最少知识原则其核心思想指的是:只和你的朋友(出现在成员变量、方法中的参数类)谈话。
实际应用举例
这个原则是指导我们尽量减少对象间的交互,对象之和自己的朋友谈话交互。减少类之间的耦合度,降低修改带来的风险。
我们看下面这个项目开发的例子,CTO发布指令给项目经理安排开发人员进行开发,开发步骤分别有3个步骤:设计、编码、测试,每个步骤通过后才能进行下一步,单元测试通过后就可以提交代码了。
根据上面设计,编码如下:
- CTO发送指令给项目管理员
public class CTO {
/**
* 安排项目管理员去跟踪项目
* @param projectLeader
*/
public void command(ProjectLeader projectLeader){
DevEngineer devEngineer = new DevEngineer("三台");
projectLeader.notifyDev(devEngineer);
}
}
- 项目管理员通知开发人员进行开发,并根据结果控制步骤
public class ProjectLeader {
/**
* 通知开发人员进行相关任务步骤
* @param engineer 开发人员
*/
public void notifyDev(DevEngineer engineer){
int design = engineer.design();
if(design >= 60){
int code = engineer.code();
if(code >= 60){
int test = engineer.test();
if(test >= 60){
System.out.println("开发任务完成可以提交代码了!");
}else {
System.out.println("不合格,单元测试覆盖率不足!");
}
}else {
System.out.println("不合格,代码需要重构!");
}
}else {
System.out.println("不合格,重新回去设计!");
}
}
}
- 开发人员进行开发
public class DevEngineer {
private String name;
private Random rand = new Random(System.currentTimeMillis());
public DevEngineer(String name) {
this.name = name;
}
/**
* 设计
* @return 任务得分
*/
public int design(){
System.out.println(this.name + " 进行开发任务的设计和文档编写工作......");
return rand.nextInt(100);
}
/**
* 编码
* @return 任务得分
*/
public int code(){
System.out.println(this.name + " 进行编码,愉快的编码中......");
return rand.nextInt(100);
}
/**
* 单元测试
* @return 任务得分
*/
public int test(){
System.out.println(this.name + " 编码完成进行单元测试......");
return rand.nextInt(100);
}
}
- 客户端测试下这个场景
public class Client {
public static void main(String[] args) {
CTO cto = new CTO();
cto.command(new ProjectLeader());
}
}
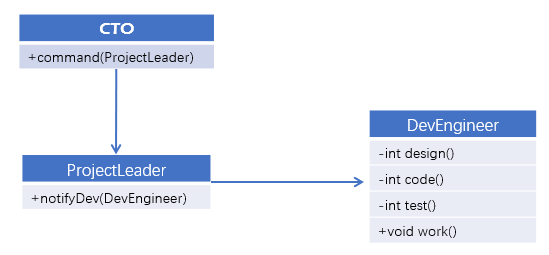
上面的代码满足我们定义的需求,但是有没有存在一些问题呢?类图关系如下:

很明显它违背了最少知识原则,具体体现在二个方面:
- 开发人员不是CTO的朋友,项目管理员才是
- 项目管理员这位朋友太亲密了,简直手把手指导开发了
对上述代码改造如下:
- CTO类只和项目管理员打交道
public class CTO {
/**
* 安排项目管理员去跟踪项目
* @param projectLeader
*/
public void command(ProjectLeader projectLeader){
projectLeader.notifyDev();
}
}
- 项目管理员去通知具体的开发人员,只要通知他们开始开发工作就行了
public class ProjectLeader {
/**
* 通知开发人员进行相关任务步骤
*/
public void notifyDev(){
DevEngineer devEngineer = new DevEngineer("三台");
devEngineer.work();
}
}
- 开发人员只提供一个对外的方法,就是要不要开始进行工作,工作步骤按照固定流程来即可
//篇幅原因,具体步骤等方法就不展示了,主要从public换成了private
......
public void work(){
int design = this.design();
if(design >= 60){
int code = this.code();
if(code >= 60){
int test = this.test();
if(test >= 60){
System.out.println("开发任务完成可以提交代码了!");
}else {
System.out.println("不合格,单元测试覆盖率不足!");
}
}else {
System.out.println("不合格,代码需要重构!");
}
}else {
System.out.println("不合格,重新回去设计!");
}
}
.......
通过修改后的关系类图如下:
修改后我们的代码很好的符合了最少知识原则,只有朋友之间才会打交道,打交道的朋友之间也保持了一定的距离。
原则建议
要正确使用这个原则,首先要弄清楚哪些是朋友呢?:
- 当前对象本身
- 通过方法参数传递进来的对象
- 当前对象所创建的对象
- 当前对象实例所引用的对象
- 方法内创建或实例化的对象
上面的指导告诉我们如何区分朋友,但是朋友的关系也不能太近,就如两个刺猬取暖:太远取不到暖,太近容易互相伤害。
人类交朋友有个邓巴数(150人左右)和形容关系连接的六度空间理论,那么最少知识原则是否也能给我们提供一个适合OOD邓巴数呢?
这里推荐一个自己自创的概念:迪比特二度空间理论,意思就是跳转二次才访问到一个类时,就需要考虑重新设计你的代码了。最后请心里时刻谨记:尽量减少对象的依赖。
开放关闭原则

核心思想
所谓开闭原则其核心思想指的是:对修改关闭,对扩展开放。
它要求类的行为是可以扩展的,但是不能对其修改。怎么听起来有种又想马儿不吃草,又想马儿跑的快的赶脚?
实现其关键方法就是合理地抽象、分离出变化和不变化的部分。为变化的部分预留可扩展的方式,比如:钩子方法或动态组合对象等
实际应用举例
比如我们有一个纺织类ERP销售系统,正在售卖一些刺绣类的商品,目前实现类图如下:
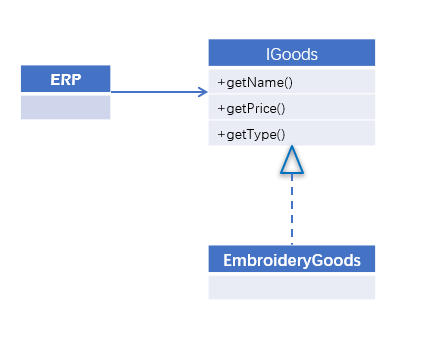
现在公司业务发展需要,进行一波打折促销,我们如何实现该需求呢?大致上有三种方法可以实现:
- 修改现有的接口:在IGoods中增加一个打折的方法,专门用来打折,所有的实现类都要实现该方法。后果是类图中的所有角色参与修改,如果其他商品不打折也得实现打折方法。
- 修改实现类:直接在刺绣类的逻辑中修改,这样也仅仅修改一个类,不对其他商品类产生影响。后果:如果有其他人员要查看原价,调用这个获取价格的方法就有问题了。
- 通过扩展实现类:用新的实现类继承原来的实现类,覆盖getPrice方法,修改少风险小,推荐。
修改后的类图如下:
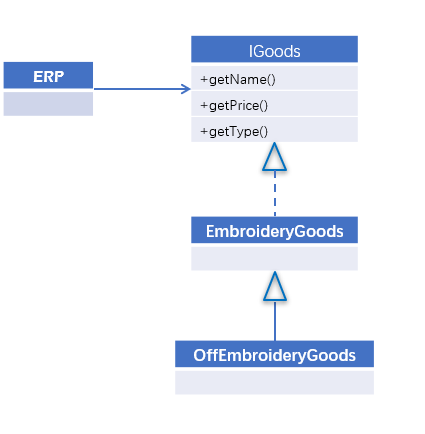
- 其他设计方法:接口一开始就预留打折的方法,具体计算看配置;模板方法获取原价;修饰器模式等
原则建议
不要追求完美的开闭原则,就像现实不存在又帅又有钱又专一又浪漫又整天陪你又事业有成的男人。适度的抽象可以提高系统的灵活性,过度的抽象会大大提升系统的复杂度。
一般情况下我们会采用继承的方式来进行扩展。
带来的好处:在不用修改源代码(原来代码)的情况下,对功能进行扩展意味着不会影响到以前的功能代码,保障了系统升级新功能的可靠性。也大大减轻了测试的工作量。
可能的坏处:把握不当会陷入过度设计
使用难点:看起来是很简单,但事实上,一个系统要全部遵守开闭原则,几乎是不可能的,也没有这个必要。在对核心业务上进行适度的抽象,运用二八法则进行开闭原则的实施是一个不错的选择。
小结
除了以上介绍的六大原则,其实还设有其它一些OOD的设计思想,比如面向接口编程,优先使用组合而不是继承,数据应该隐藏在类内部,类之间最好只有传到耦合,在水平方向上尽可能统一地分布系统功能等等。
但是我们要清楚认识到设计原则是思想层面的高度概括,也只是一个建议指导。请结合自己实际情况根据系统规模和业务特点合理的使用它们。